趁热打铁,学习一下 APScheduler 的 python 的源码,很好奇任务调度控制的实现。
分析源码主要还是针对 APScheduler 下的几个关键的模块
events事件executors执行器job任务jobstores任务存储triggers触发器schedulers调度程序
终于来到最核心的 schedulers 部分的源码分析了,在将其他模块都介绍完之后, schedulers 最核心的部分是如何将它们拼接起来
总览
先总览一下文件夹下的目录结构
简单整理一下类结构
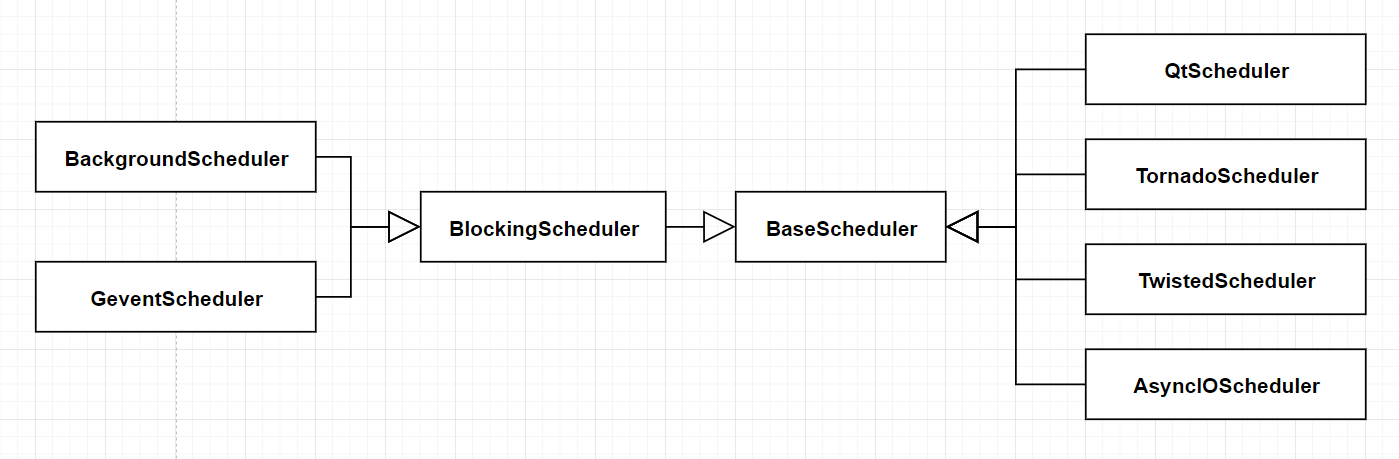
可以看出这里比较核心的 2 个类就是 BaseScheduler 和 BlockingScheduler , 所以接下来我也主要从这 2 个类着手,介绍完整的 schedulers 的操作流程
BaseScheduler
作为基类,封装并提供了协调其他模块的接口,因为其他模块源码都分析完了,防止不熟悉每个模块提供的功能,这里再简单回顾一下,加深对它们的印象,也方便展开 BaseScheduler 的介绍
| 模块 | 模块描述 | 接口 | 接口描述 |
|---|---|---|---|
| job | 任务的封装 | _modify() | 主要就是更新 job |
| _get_run_times() | 获取任务下次执行的时间 | ||
| pause(), resume(), remove() … | 暂停,恢复,删除任务等 | ||
| jobstores | 任务存储 | start() | 初始化任务存储 |
| shutdown() | 停止 | ||
| get_next_run_time() | 返回任务存储中最新的下一次执行的任务 | ||
| get_due_jobs() | 获取所有下次执行时间早于 now 的任务 |
||
| add_job(),update_job(),get_all_jobs() … | 向任务存储中添加任务,更新任务, 获取所有任务等 | ||
| executors | 执行器 | start() | 初始化执行器 |
| shutdown() | 停止 | ||
| submit_job() | 提交 job 让执行器执行 |
||
| triggers | 触发器 | get_next_fire_time() | 结合上次执行时间和当前时间算出 job 的下次执行时间 |
| 初始化 | 不同的子类区分不同的初始化参数 | ||
| schedulers | 任务调度 | start() | 初始化任务调度 |
| shutdown() | 停止 | ||
| pause(),resume() | 暂停,恢复任务调度 | ||
| add_jobstore(), remove_jobstore() | 添加,删除任务存储 | ||
| add_job(),modify_job(),pause_job(),resume_job() … | 添加,修改,暂停,恢复任务等 | ||
| _real_add_job() | (真正,相对于 add_job() 函数)添加 job 时,对任务的处理 |
||
| add_executor(), remove_executor() | 添加,删除执行器 | ||
| add_listener(), remove_listener() | 添加,删除侦听器 | ||
| _dispatch_event() | 将给定事件调度给侦听器。 | ||
| _process_jobs() | 任务调度的核心 | ||
| _create_default_executor(),_create_default_jobstore() | 初始化默认模块 | ||
| _create_plugin_instance(),_create_trigger() … | 创建模块等函数 |
大致就这些接口,一部分很简单的接口就没有罗列了,接下来我主要从模块初始化的方式,任务的控制,BaseScheduler 启动暂停等控制方式,任务执行调度等几个方面介绍 BaseScheduler
模块初始化和控制
介绍模块化之前,首先先看一个例子
REDIS = {
'host' : "192.168.0.123",
'port' : 6379,
'db': 0
}
jobstores = {
'test_redis': RedisJobStore(**REDIS),
'default' : MemoryJobStore()
}
# 第一种
scheduler = BlockingScheduler(jobstores=jobstores)
# 第二种
scheduler = BlockingScheduler()
scheduler.add_jobstore(jobstore=RedisJobStore(**REDIS), alias='test_redis')
scheduler.add_jobstore(jobstore=MemoryJobStore(), alias='default')
# 第三种
scheduler = BlockingScheduler()
scheduler.add_jobstore(jobstore='redis', alias='test_redis', **REDIS)
scheduler.add_jobstore(jobstore='memory', alias='default')
这里有三种添加一个 jobstore 的方式
- 第一种 : 初始化
BlockingScheduler直接将jobstores这个对象传递进去,test_redis和default是对应jobstore的别名 - 第二种 :
add_jobstore()函数中jobstore直接对应具体的jobstore对象,然后设置对应别名alias - 第三种 :
add_jobstore()函数中jobstore填写官方对应的别名,alias为用户设置的别名,同时需要传入初始化这个jobstore的额外参数**REDIS
如果按照正常的逻辑,scheduler 作为统筹所有模块的类,需要 import xxx 导入所有相关模块,那么 BaseScheduler (BlockingScheduler的基类) 就需要导入 MemoryJobStore 和 RedisJobStore, 第三种方式还需要根据 memory 找到 MemoryJobStore,redis 找到 RedisJobStore 等等
那么随着代码的开发,之后可能会随着能够兼容的框架越多,会增加越来越多的子类,BaseScheduler 每次都需要改动,此时就需要解决在添加某个模块子类,就要改动 BaseScheduler 代码的问题
所以 BaseScheduler 使用了 pkg_resources 库下的 iter_entry_points,来插件化的实现模块的导入,它在 entry_points.txt 定义了所有需要导入的类,格式是有固定要求的
[apscheduler.executors]
asyncio = apscheduler.executors.asyncio:AsyncIOExecutor [asyncio]
debug = apscheduler.executors.debug:DebugExecutor
gevent = apscheduler.executors.gevent:GeventExecutor [gevent]
processpool = apscheduler.executors.pool:ProcessPoolExecutor
threadpool = apscheduler.executors.pool:ThreadPoolExecutor
tornado = apscheduler.executors.tornado:TornadoExecutor [tornado]
twisted = apscheduler.executors.twisted:TwistedExecutor [twisted]
[apscheduler.jobstores]
memory = apscheduler.jobstores.memory:MemoryJobStore
mongodb = apscheduler.jobstores.mongodb:MongoDBJobStore [mongodb]
redis = apscheduler.jobstores.redis:RedisJobStore [redis]
rethinkdb = apscheduler.jobstores.rethinkdb:RethinkDBJobStore [rethinkdb]
sqlalchemy = apscheduler.jobstores.sqlalchemy:SQLAlchemyJobStore [sqlalchemy]
zookeeper = apscheduler.jobstores.zookeeper:ZooKeeperJobStore [zookeeper]
[apscheduler.triggers]
and = apscheduler.triggers.combining:AndTrigger
cron = apscheduler.triggers.cron:CronTrigger
date = apscheduler.triggers.date:DateTrigger
interval = apscheduler.triggers.interval:IntervalTrigger
or = apscheduler.triggers.combining:OrTrigger
源码中只要简简单单的这样就能记录下来, 其中 ep.name 就是子类官方的别名, ep 需要通过 load() 来加载类对象
_trigger_plugins = dict((ep.name, ep) for ep in iter_entry_points('apscheduler.triggers'))
_executor_plugins = dict((ep.name, ep) for ep in iter_entry_points('apscheduler.executors'))
_jobstore_plugins = dict((ep.name, ep) for ep in iter_entry_points('apscheduler.jobstores'))
那么真正使用的时候就是在 _create_plugin_instance 函数中
def _create_plugin_instance(self, type_, alias, constructor_kwargs):
# 根据 `type_` 来区分获取3个值
# plugin_container 所有插件,也就是通过 `iter_entry_points` 导入的
# class_container 已经导入过的类
# base_class 对象的基类
plugin_container, class_container, base_class = {
'trigger': (self._trigger_plugins, self._trigger_classes, BaseTrigger),
'jobstore': (self._jobstore_plugins, self._jobstore_classes, BaseJobStore),
'executor': (self._executor_plugins, self._executor_classes, BaseExecutor)
}[type_]
try:
# 如果已经导入过,直接得到插件类
plugin_cls = class_container[alias]
except KeyError:
# 判断用户传入的别名是否存在于导入的 `plugin_container`
if alias in plugin_container:
# 导入别名是 `alias` 的类
plugin_cls = class_container[alias] = plugin_container[alias].load()
# 为了防止外层文件被人修改,加了一次额外的判断,最起码判断一下这个类的基类是否一样
if not issubclass(plugin_cls, base_class):
raise TypeError('The {0} entry point does not point to a {0} class'.
format(type_))
else:
raise LookupError('No {0} by the name "{1}" was found'.format(type_, alias))
# 最后实例化创建
return plugin_cls(**constructor_kwargs)
这一部分的思路还是很值得学习的,插件化的控制类的加载和导入,后期就算添加再多的其他子类,最起码这个类也不需要任何改动,只需要改动类的外层依赖文件 entry_points.txt
add_jobstors() 会根据 jobstore 变量的类型来区分是第二种还是第三种,第三种的 str 类型话,就需要使用上面的方式来实例化
接下来 BaseScheduler 将实例化对象对应的保存到对应 self._executors (dict), self._jobstores (dict) 的成员变量中,具体的样式为
# 以 `alias` 作为 `key`,对应的对象作为 `value`,删除的时候也对应从成员变量中删除即可
{"aliasA" : classA, "aliasB":classB}
而 trigger 是保存到对应的 job 中,所以接下来看一下 scheduler 对 job 的控制
任务的控制
任务的控制,可以简单的理解成向指定的 jobstore 中添加,删除,以及通过 job 的 _modify 来修改任务的存储的信息
这一部分实际上只有一个需要注意的地方,BaseScheduler 中引入了 self._pending_jobs 这个 list 对象在某些条件下保存待添加的任务
首先需要知道一点 BaseScheduler 有以下几个状态
# 停止状态,调用 `start()` 前的状态,也就是默认状态
STATE_STOPPED = 0
# 运行中的状态
STATE_RUNNING = 1
# 暂停的状态
STATE_PAUSED = 2
在不同的 BaseScheduler 运行状态下,添加任务实际上的操作是有一定出入的
停止状态: 将任务先添加进self._pending_jobs变量中,在程序调用start()之后,从self._pending_jobs取出,调用_real_add_job()函数来添加运行状态和暂停状态: 直接调用_real_add_job()函数来添加
这里我简单说一下 _real_add_job(job, jobstore_alias, replace_existing) 函数大致的逻辑
- 检测任务是否设置了
next_run_time,如果没有,则通过调用job里设置的触发器下的函数trigger.get_next_fire_time(None, now)计算出时间,然后调用job的_modify()函数来更新 - 根据传入的
jobstore别名, 从self._jobstores中找到对应的jobstore对象,然后在根据replace_existing字段判断添加或者更新,调用jobstore对象的add_job()或者update_job接口 - 通过
self._dispatch_event()函数将 任务添加的事件(EVENT_JOB_ADDED) 传递给监听器 - 如果当前
STATE_RUNNING状态,调用self.wakeup()函数,大致作用就是通知一下BaseScheduler有改动,记得刷新一下
删除 remove_job() 也需要根据BaseScheduler 运行状态来决定是从 self._pending_jobs 中删除还是从 jobstore 中删除
剩余的查询等接口的实现理解起来都很简单就不赘述了
启动暂停等控制
BaseScheduler 的控制实际上就 4 种 pause(), resume(), start(), shutdown(),其实主要就是更新它的状态 self.state,并且完成一些额外的操作
以 start(paused=False) 为例 这里 pause=False 的时候,就是正常启动,pause=True 是暂停状态,那么还需要调用 resume() 才能真正启动
- 调用所有的
executor的start() - 调用所有的
jobstore的start() - 将
self._pending_jobs中所有的任务通过self._real_add_job()函数真正添加到jobstore中 - 根据
paused设置状态self.state状态是STATE_RUNNING还是STATE_PAUSED - 通过
self._dispatch_event()函数将 启动的事件(EVENT_SCHEDULER_START) 传递给监听器 - 最后如果
paused=False调用self.wakeup()函数
此外还有一个 wakeup() 函数,这在 BaseScheduler 中实际上是一个抽象方法,交给子类自己实现,它的目的就是当计划有改变,通知子类记得 “刷新”
所以在 start(),resume(),add_jobstore(),modify_job() 以及 _real_add_job() 都需要 wakeup() 一下
任务执行的调度
终于来到最核心的部分了,任务的执行的处理函数 _process_jobs()
简单点说,它的作用就是: 遍历每个 jobstore 中的 job,执行到期的 job ,并计算出当前时间到下一轮的时间差,也就是等待唤醒的时间。
虽然需要结合 BaseScheduler 的 self.state 做一些额外的判断, 但是整体的代码逻辑不是很复杂,不过有个很有意思的设计点,感觉还是值得说一下
假设我的任务计划是每隔 20秒 执行一次,任务的开始时间是 2021-04-10 22:13:00,我简单理一下从调用 start() 开始到任务执行 1 次的流程
- 调用
start()后,会真正添加任务,此时会先计算一下next_run_time的值, 假设当前时间是2021-04-10 22:13:09.347022
那么下次执行时间是2021-04-10 22:13:20, 这个值会更新进job中,最后调用weakup(),通知刷新,然后开始调用_process_jobs() - 调用
_process_jobs()时获取的当前时间和调用start()函数获取的当前时间肯定是有一定误差的,但是很小,可能只有零点零几毫秒
所有这里假设_process_jobs()获取的当前时间是2021-04-10 22:13:09.400000
在轮训完jobstore中所有job的next_run_time,发现最近的一次执行时间是2021-04-10 22:13:20,所以不用取出任务执行,然后需要算出休眠时间,也就是这2个值的差值,就是10.6秒 10.6秒后也就是2021-04-10 22:13:20重新执行_process_jobs()函数, 但是_process_jobs()调用时获取的当前时间肯定是一个略大于这个时间的一个值
假设2021-04-10 22:13:20.015235, 此时通过jobstore的get_due_jobs(now)获取 不大于当前时间 的任务, 然后交给executor执行,并且还需要计算出的下一次执行时间, 也就是2021-04-10 22:13:40,并更新到job中
那么接下来的休眠时间是下一次执行时间2021-04-10 22:13:40与2021-04-10 22:13:20.015235的差值19.984765秒19.984765秒后将会再次执行_process_jobs()函数 …
如果这样看的话,其实每次执行的任务都是一个过期一个很小时间的任务
平时接触 Qt 比较多,所以在我的思维逻辑里,使用 Qt 的定时器就可以实现这样的调度,而源码中这样的设计还是挺耳目一新的
备注: 这里面很多操作都需要在的加锁情况执行, 比如添加 job 到 jobstore, 或者从 jobstore 中查询 job 等等
BlockingScheduler
在前台运行的调度程序, 也就是阻塞式的任务调度方式
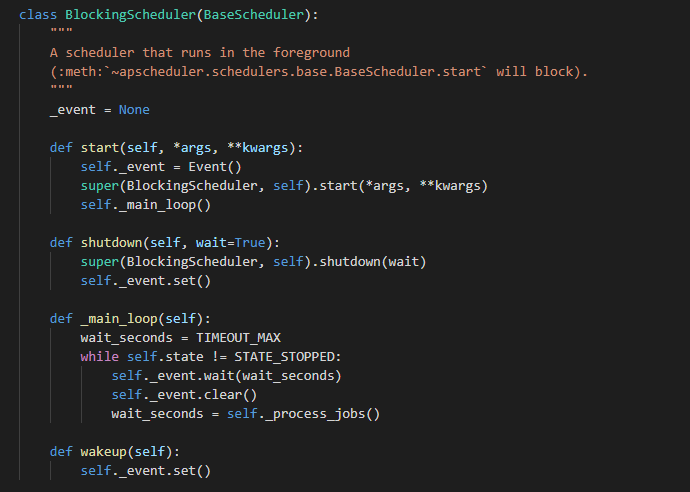
BlockingScheduler 这里有一个比较核心点 threading.Event
首先先看 官方说明, 接口都很简单
isSet(): 当内置标志为True时返回True。set(): 将内部标志设置为True。所有正在等待这个事件的线程将被唤醒。clear(): 将内部标志设置为False。wait(timeout=None): 阻塞线程直到内部变量为True。如果调用时内部标志为True,将立即返回。否则将阻塞线程,直到调用set()方法将标志设置为True或者发生可选的超时。
BlockingScheduler 并不是一直 while True 来遍历所有任务,而是结合 BaseScheduler 中的状态, 在执行任务后,会根据下一个任务的执行时间,算出一个休眠的时间,通过 self._event.wait(wait_seconds) 来避免一直进行无效的循环
其他子类
BackgroundScheduler(BlockingScheduler的子类),通过将父类的self._main_loop()函数扔进一个新的线程中,来实现后台运行QtScheduler(BaseScheduler的子类), 使用定时器的形式调用父类的self._process_jobs()函数
其他子类这里就不介绍了,感兴趣的可以自己看看,都是基于一些其他框架下提供的接口,应该难度也不大
总结
终于把 APScheduler 的源码部分核心部分的实现全部整理完了, 让我很感兴趣的主要有 2 点
CronTriger触发器的实现, 针对时间的每一字段做设置, 计算下次执行时间的逻辑很有意思BaseScheduler的任务执行调度的实现_process_jobs()也很有意思
总之 APScheduler 的源码阅读, 完结撒花~~~