趁热打铁, 学习一下 APScheduler 的 python 的源码, 很好奇任务调度控制的实现。
分析源码主要还是针对 APScheduler 下的几个关键的模块
events事件executors执行器job任务jobstores任务存储triggers触发器schedulers调度程序
这一篇主要瞅瞅 triggers 触发器
前文已经介绍了基类 BaseTrigger 以及在固定时间执行一次的 DateTrigger 和以固定时间间隔运行任务的 IntervalTrigger, 这篇文章会主要介绍超强大,但是也是最复杂的 CronTrigger
简介
我们知道 DateTrigger 是只执行一次的定时器, IntervalTrigger 是按照固定时间间隔反复执行的定时器, 那么当我们需要例如 每个周六周日每隔10S 执行的定时器的时候, CronTrigger 就能很好的来处理. CronTrigger 定义一个匹配规则, 在时间与指定规则匹配时触发
在之前的 API总结 中提到了支持匹配的字段和匹配的表达式格式, 这里再次展示一下, 方便结合源码思考实现的细节
year(int|str)4位数的年份month(int|str)month (1-12 或者 ‘jan’, ‘feb’, ‘mar’, ‘apr’, ‘may’, ‘jun’, ‘jul’, ‘aug’, ‘sep’, ‘oct’, ‘nov’, ‘dec’)day(int|str)(1-31) 天week(int|str)ISO 周 (1-53)day_of_week(int|str)工作日的编号或名称 (0-6 or mon,tue,wed,thu,fri,sat,sun)hour(int|str)小时(0-23)minute(int|str)分钟(0-59)second(int|str)秒(0-59)
而这些字段支持的表达式格式 (并不是每个字段都同时支持) 如下:
| 表达式 | 匹配依靠的类 | 描述 |
|---|---|---|
| */a | AllExpression | 从 a 值开始, 触发每个 a 值 |
| a-b/c | RangeExpression | 在 a-b 范围内触发每个 c 值 |
| xth y | WeekdayPositionExpression | 在一个月中第 x 个 周 y 触发 ( x 支持的参数 1st, 2nd, 3rd, 4th, 5th, last) |
| last | LastDayOfMonthExpression | 在一个月的最后一天触发 |
| x,y,z | 可以用逗号隔开多个表达式 |
所以在理解 CronTrigger 的时候,我想先介绍一些关于这些表达式解析部分的源码
表达式解析
这一部分实现主要在文件 expressions.py 中, 其中类的结构如下图, 接下来我们结合这几个类, 详细看一下实现
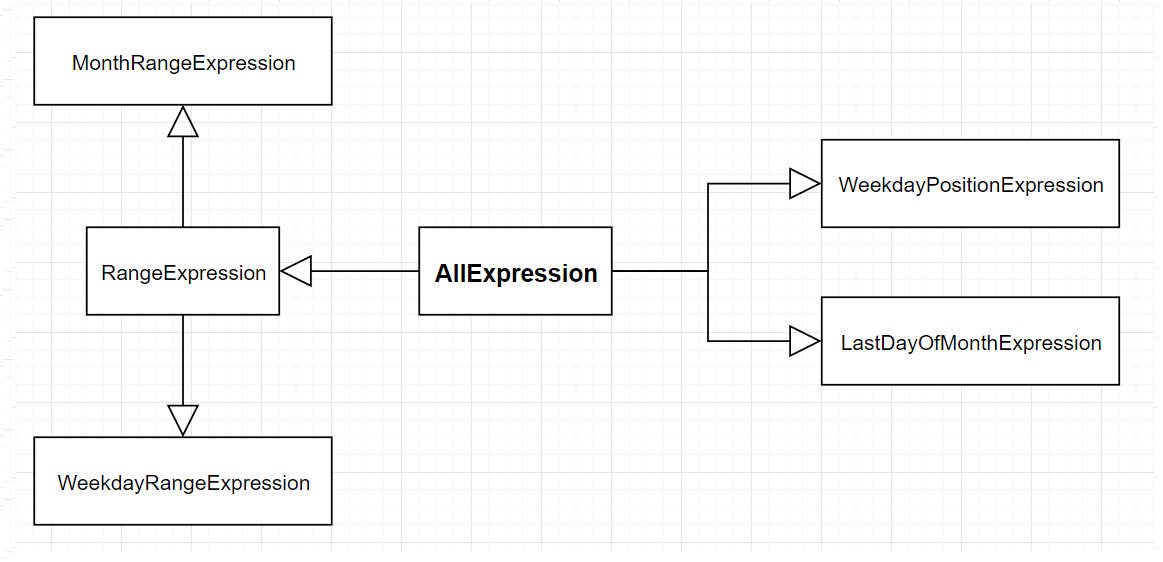
- 以
AllExpression为基类的 3 个子类RangeExpression,WeekdayPositionExpression和LastDayOfMonthExpression - 以
RangeExpression为基类的 2 个子类WeekdayRangeExpression和WeekdayPositionExpression
接下来我们从 AllExpression 开始看
AllExpression
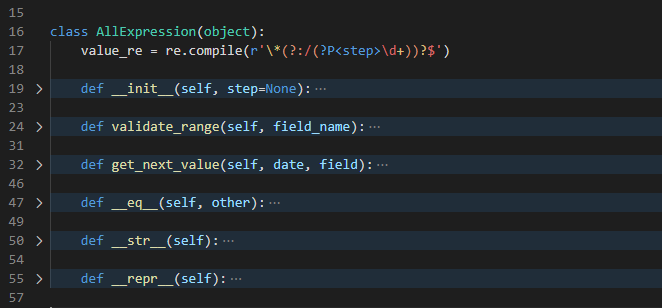
正则表达式
value_re = re.compile(r'\*(?:/(?P<step>\d+))?$')
这一块我不是很精通,没法很细节的解释,只能大致说一下我的理解
re.compile()函数编译正则表达式,生成一个正则表达式的对象, 而且如果正则表达式的字符串本身不合法, 会报错;
之后通过match = value_re.match(expr)来匹配字符串expr
等同于match = re.match(r'\*(?:/(?P<step>\d+))?$', expr)- 正则表达式中, 实际上匹配的是形如
*/5这种格式的字符串, 对于*/5这种格式,通过match.groupdict()得到的匹配结果是{'step': '5'}
这里还有一个细节的地方, 是通过 ?:(非捕获分组) 来捕获 step 这个字段, 简单点说, 如果写成 *, 那么 step 就是 None
初始化
初始化就是一个很简单的将 step 转成 int 类型并赋值给 self.step, 注意 step 是不能为 0 的.
def __init__(self, step=None):
self.step = asint(step)
if self.step == 0:
raise ValueError('Increment must be higher than 0')
注意
step虽然不能为0, 但是可以是None
validate_range()
def validate_range(self, field_name):
from apscheduler.triggers.cron.fields import MIN_VALUES, MAX_VALUES
value_range = MAX_VALUES[field_name] - MIN_VALUES[field_name]
if self.step and self.step > value_range:
raise ValueError('the step value ({}) is higher than the total range of the '
'expression ({})'.format(self.step, value_range))
这个函数的作用简单点说就是检测步长是否是有效的, 这个有效其实是开发者定义的, 举个例子
MIN_VALUES = {'year': 1970, 'month': 1, 'day': 1, 'week': 1, 'day_of_week': 0, 'hour': 0,
'minute': 0, 'second': 0}
MAX_VALUES = {'year': 9999, 'month': 12, 'day': 31, 'week': 53, 'day_of_week': 6, 'hour': 23,
'minute': 59, 'second': 59}
hour 最大值是 23, 最小值是 0, 那么 step 的步长范围就是 [1,23], 毕竟大于 23 的时候, 可以用 day 这个字段来取代 hour 字段了
get_next_value()
def get_next_value(self, date, field):
start = field.get_value(date)
minval = field.get_min(date)
maxval = field.get_max(date)
start = max(start, minval)
if not self.step:
next = start
else:
distance_to_next = (self.step - (start - minval)) % self.step
next = start + distance_to_next
if next <= maxval:
return next
乍一看有点乱, field 参数是啥, date 参数是啥, 因为还没有介绍 CronTrigger, 这里先有个印象
date简单点就是上次执行时间, 但是它在上层做了一些额外的处理, 比如向上取整field简单点说就是封装了year,month等等这些字段的一个类, 它提供这些字段 最大值, 最小值的查询以及管理这些字段对应的表达式解析的流程
举个例子, date 为 2021-03-28 02:13:09, field 是基于 second 字段封装的类
start从date中获取second的结果是 9second字段对应的最小值minval是 0, 最大值maxval是 59- 新的
start是旧的start与minval的最大值, 也就是 9
之后就是根据 self.step 是否设置了, 来决定具体的计算
- 如果 没有设置, 等于直接返回了
date中对应field字段的值 - 如果 设置了, 需要计算下次的执行时间, 就需要根据步长来决定
举个更详细的例子,date时间还是 2021-03-28 02:13:09, 假设CornTrigger定义了second='*/10', 也就是每隔 10 秒执行1次
按照这个匹配规则, 对于second这个字段就是当它的值是0, 10, 20, 30, 40, 50时执行
我们需要根据当前date去算下一个second值是多少,distance_to_next其实就是date的9(09) 距离下一个值10的差值, 也就是 1 - 如果得到的
next小于等于maxval, 则返回next, 否则返回None, 避免出现例如60等无效值
很详细的介绍了最基本的 */step 这种格式, 接下来在介绍一下其他几种的匹配表达式
RangeExpression
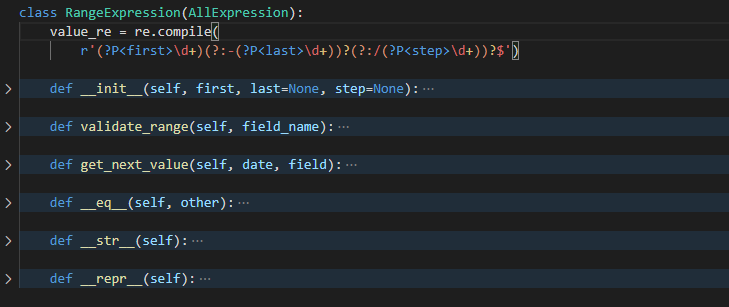
继承自 AllExpression, 一模一样的接口, 主要还是需要看它匹配的正则表达式的格式
正则表达式
value_re = re.compile(r'(?P<first>\d+)(?:-(?P<last>\d+))?(?:/(?P<step>\d+))?$')
简单点就是匹配 first-last/step 这样的格式
但是 last 和 step 的捕获使用的是 ?: 这种非捕获分组, 所以它们匹配之后是可以为 None 的, 可以其中一个字段为 None, 甚至 2 个字段都可以为 None
初始化
def __init__(self, first, last=None, step=None):
super(RangeExpression, self).__init__(step)
first = asint(first)
last = asint(last)
if last is None and step is None:
last = first
if last is not None and first > last:
raise ValueError('The minimum value in a range must not be higher than the maximum')
self.first = first
self.last = last
很正常的初始化, 需要保证 first 和 last 值的有效性, 可以其中一个字段为 None, 甚至 2 个字段都可以为 None, 所以分为 3 种情况 (匹配的表达式均以 second 为例, 其他字段都不设置)
- 都为
None, 匹配的表达式为second='30', 按照初始化的逻辑last = first, 这意味着一个字段的周期内执行一次. 以second为例, 那么1分钟内只会在 30(first) 秒的时候执行一次 last为None, 匹配的表达式为second='30/2', 意思就是从 30(first) 秒开始每隔 2(step) 执行一次, 这里的last其实就是second的最大值 59step为None, 匹配的表达式为second='30-50', 意思就是在 30(first) 秒 - 50(last) 秒之间, 每隔 1(step) 秒执行一次
直接说1秒执行一次是 错误的, 实际上是上层会对date向上取整一次 (dateval + timedelta(seconds=1, microseconds=-dateval.microsecond)), 这时候step等于None的时候, 会直接返回date对应的second的值, 看上去就是隔 1 秒执行一次
这种情况下, 其实涵盖的范围还挺广, 这样的设计感觉也很合适
validate_range()
判断字段是否是合理的, 主要就是判断 first 和 last 是否在最小值最大值之间, 以及不为 None 的 step 是否小于 last-first 代码其实很简单,不贴代码了
get_next_value()
def get_next_value(self, date, field):
startval = field.get_value(date)
minval = field.get_min(date)
maxval = field.get_max(date)
# Apply range limits
minval = max(minval, self.first)
maxval = min(maxval, self.last) if self.last is not None else maxval
nextval = max(minval, startval)
# Apply the step if defined
if self.step:
distance_to_next = (self.step - (nextval - minval)) % self.step
nextval += distance_to_next
return nextval if nextval <= maxval else None
看过 AllExpression 的 get_next_value() 就会发现, RangeExpression 其实只是结合 first 和 last 修正了最大值和最小值, 思路都是一样
不过怀疑这部分代码不是一个人实现的, 看他其他的代码基本不写 return ... else None, 哈哈, 吐槽一下~
MonthRangeExpression
从类的名称就很明显, 这是一个关于 month 这个字段的特殊的表达式解析的类
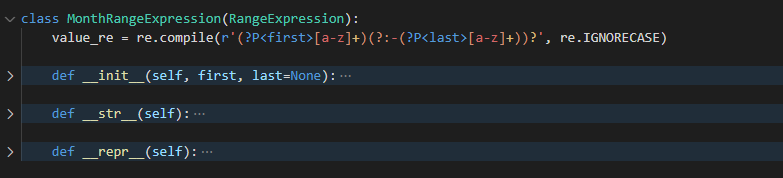
正则表达式
MONTHS = ['jan', 'feb', 'mar', 'apr', 'may', 'jun', 'jul', 'aug', 'sep', 'oct', 'nov', 'dec']
value_re = re.compile(r'(?P<first>[a-z]+)(?:-(?P<last>[a-z]+))?', re.IGNORECASE)
这里只支持解析 MONTHS 中定义的字段, 其他部分跟它的父类 RangeExpression 没有什么区别, last 也是可以为 None, 但是不同点是 step 一定是 None
初始化
def __init__(self, first, last=None):
try:
first_num = MONTHS.index(first.lower()) + 1
except ValueError:
raise ValueError('Invalid month name "%s"' % first)
if last:
try:
last_num = MONTHS.index(last.lower()) + 1
except ValueError:
raise ValueError('Invalid month name "%s"' % last)
else:
last_num = None
super(MonthRangeExpression, self).__init__(first_num, last_num)
这一部分很简单, 主要注意一下这里 +1 的操作, list 是从 0-11, 但是日期实际上展示的时候是从 1-12
WeekdayRangeExpression
这是针对 day_of_week 字段定义的一个特殊的表达式解析的类
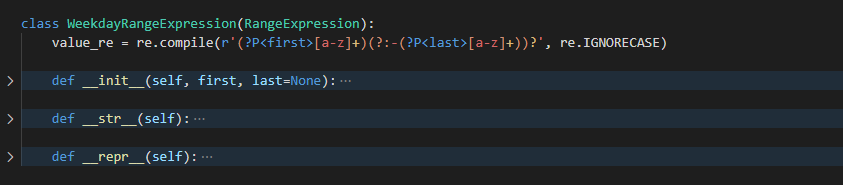
正则表达式
WEEKDAYS = ['mon', 'tue', 'wed', 'thu', 'fri', 'sat', 'sun']
value_re = re.compile(r'(?P<first>[a-z]+)(?:-(?P<last>[a-z]+))?', re.IGNORECASE)
和 MonthRangeExpression 差不多, 就不解释了
初始化
def __init__(self, first, last=None):
try:
first_num = WEEKDAYS.index(first.lower())
except ValueError:
raise ValueError('Invalid weekday name "%s"' % first)
if last:
try:
last_num = WEEKDAYS.index(last.lower())
except ValueError:
raise ValueError('Invalid weekday name "%s"' % last)
else:
last_num = None
super(WeekdayRangeExpression, self).__init__(first_num, last_num)
代码很简单, 就不解释了~
LastDayOfMonthExpression
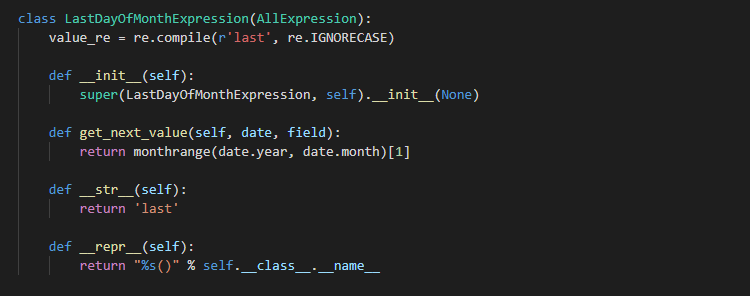
LastDayOfMonthExpression 是针对 month 字段一个正则表达式解析类
这个部分就一个重载的函数 get_next_value(), monthrange() 函数是 calendar 库中的一个函数, 就是返回一个月第一天是周几(0-6), 以及这个月一共有多少天~
def monthrange(year, month):
"""Return weekday (0-6 ~ Mon-Sun) and number of days (28-31) for
year, month."""
if not 1 <= month <= 12:
raise IllegalMonthError(month)
day1 = weekday(year, month, 1)
ndays = mdays[month] + (month == February and isleap(year))
return day1, ndays
WeekdayPositionExpression
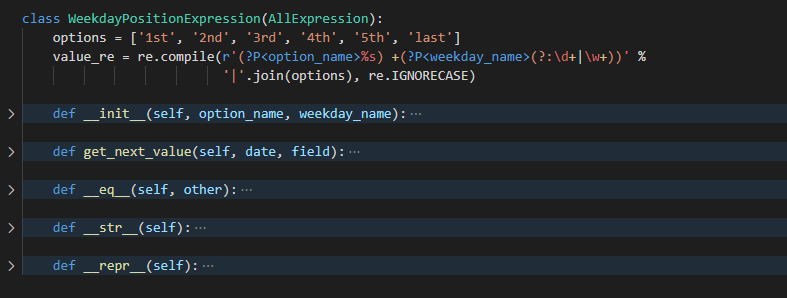
WeekdayPositionExpression 是针对 day 字段一个特殊的正则表达式解析类
正则表达式
WEEKDAYS = ['mon', 'tue', 'wed', 'thu', 'fri', 'sat', 'sun']
options = ['1st', '2nd', '3rd', '4th', '5th', 'last']
value_re = re.compile(r'(?P<option_name>%s) +(?P<weekday_name>(?:\d+|\w+))' %
'|'.join(options), re.IGNORECASE)
option_name匹配options中的字段weekday_name匹配WEEKDAYS中的字段, 虽然它也写了\d里匹配数字, 但是初始化的时候实际上用的是WEEKDAYS中的星期的简写
例如 day='2nd +mon' , 它就代表一个月里 第二个 周一
初始化
def __init__(self, option_name, weekday_name):
super(WeekdayPositionExpression, self).__init__(None)
try:
self.option_num = self.options.index(option_name.lower())
except ValueError:
raise ValueError('Invalid weekday position "%s"' % option_name)
try:
self.weekday = WEEKDAYS.index(weekday_name.lower())
except ValueError:
raise ValueError('Invalid weekday name "%s"' % weekday_name)
初始化朴实无华, 就是很简单的解析出 option_num 和 weekday
get_next_value()
def get_next_value(self, date, field):
first_day_wday, last_day = monthrange(date.year, date.month)
first_hit_day = self.weekday - first_day_wday + 1
if first_hit_day <= 0:
first_hit_day += 7
if self.option_num < 5:
target_day = first_hit_day + self.option_num * 7
else:
target_day = first_hit_day + ((last_day - first_hit_day) // 7) * 7
if target_day <= last_day and target_day >= date.day:
return target_day
前面介绍了 monthrange() 函数, 就是返回一个月第一天是周几 first_day_wday, 以及这个月总的天数 last_day
所以看一下总的逻辑:
first_hit_day其实就是第一个self.weekday是几号- 结合
self.option_num在计算出第self.option_num个self.weekday是几号 - 最后需要保证得出的
target_day必须在总的last_day以内, 以及计算出的下次target_day大于等于上次执行日期的天数date.day
判断的过程简单解释一下, 以 2021 年 4 月为例, 星期四和星期五在这个月其实出现了 5 次, 当然也只会最多出现 5 次
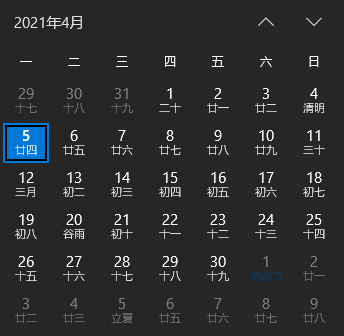
所以 self.option_num 以 5 为判断的条件
- 当表达式传入的参数是
'1st', '2nd', '3rd', '4th', '5th'它们时,也就是0-4的时候
通过first_hit_day + self.option_num * 7来得出返回的天数target_day - 当表达式传入参数时
'last'也就是5的时候, 就是求最后一个的天数
(last_day - first_hit_day) // 7)取整算出从first_hit_day到月底最多有几个first_hit_day, 然后求出target_day即可
总结
这一部分的核心就是对时间的每个字段对应的正则表达式进行封装, 上层会对时间的每个字段通过 get_next_value() 来单独获取它的 next
回想一下 AllExpression, 其实很类似 RangeExpression, 例如 second 这个字段, 按照 RangeExpression 的逻辑, 其实 first 其实就是 0, last 就是 59, 但是 AllExpression 更倾向于在一个时间最大值最小值之间每隔 step 执行一次
RangeExpression 是在 AllExpression 的基础上, 并将它更加具体化了
- 表达式
first: 是每个时间间隔中只在first位置执行一次 - 表达式
first-last/step: 是在first和last之间每隔step执行一次
其他的几个类在实现上也不是太复杂~