趁热打铁,学习一下 APScheduler 的 python 的源码,很好奇任务调度控制的实现。
分析源码主要还是针对 APScheduler 下的几个关键的模块
events事件executors执行器job任务jobstores任务存储triggers触发器schedulers调度程序
这一篇主要瞅瞅 triggers 触发器
简单回顾一下 CronTrigger 的正则表达式解析提供一些类
| 类 | 正则表达式 |
|---|---|
| AllExpression | */step* |
| RangeExpression | firstfirst-lastfirst/stepfirst-last/step |
| MonthRangeExpression | firstfirst-last |
| WeekdayRangeExpression | firstfirst-last |
| WeekdayPositionExpression | option_name weekday_name |
| LastDayOfMonthExpression | last |
这里有需要补充的一些内容
MonthRangeExpression的first和last必须匹配这些字段['jan', 'feb', 'mar', 'apr', 'may', 'jun', 'jul', 'aug', 'sep', 'oct', 'nov', 'dec'], 但是不限制大小写WeekdayRangeExpression的first和last必须匹配这些字段['mon', 'tue', 'wed', 'thu', 'fri', 'sat', 'sun'], 也不限制大小写WeekdayPositionExpression的option_name只匹配['1st', '2nd', '3rd', '4th', '5th', 'last'],weekday_name匹配的字段和WeekdayRangeExpression一样
上一篇文章回顾完了,但是这里又引入了一个新的问题,我怎么决定不同的时间字段对应哪种表达式,以及例如 'jan','feb' 这样的复合表达式如何解析等问题。
接下来介绍的 BaseField 及其子类将完成对上述问题的解释及实现
BaseField 及其子类
首先我需要在说明一下,CronTrigger 中可配置的字段最大值最小值,以及默认值如下
MIN_VALUES = {'year': 1970, 'month': 1, 'day': 1, 'week': 1, 'day_of_week': 0, 'hour': 0, 'minute': 0, 'second': 0}
MAX_VALUES = {'year': 9999, 'month': 12, 'day': 31, 'week': 53, 'day_of_week': 6, 'hour': 23, 'minute': 59, 'second': 59}
DEFAULT_VALUES = {'year': '*', 'month': 1, 'day': 1, 'week': '*', 'day_of_week': '*', 'hour': 0, 'minute': 0, 'second': 0}
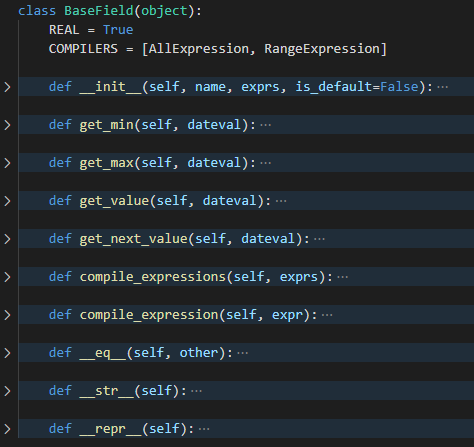
BaseField 提供了对这些 year 等字段最大值最小值获取的接口,在之前 AllExpression 的介绍中已经有看到过
def get_min(self, dateval):
return MIN_VALUES[self.name]
def get_max(self, dateval):
return MAX_VALUES[self.name]
def get_value(self, dateval):
return getattr(dateval, self.name)
所以这个类我觉得最核心的部分就是,当上层将这个字段和这个字段对应的表达式传入的时候,如何正确解析,以及利用 AllExpression 提供的get_next_value() 实现自己的 get_next_value() 供上级调用
这里还有一个注意的点
COMPILERS = [AllExpression, RangeExpression]
COMPILERS 它定义了这个 BaseField 用到的正则表达式解析的类只有 AllExpression 和 RangeExpression, 不同的子类定义的信息是有不同的
初始化
def __init__(self, name, exprs, is_default=False):
self.name = name
self.is_default = is_default
self.compile_expressions(exprs)
很简单,表示时间字段的 name,以及对应的表达式 exprs,根据配置的时候有没有配置这个字段决定是否需要配置默认值的 is_default, 但是这个字段实际上并没有被用到,上层已经根据是否为 None 的时候决定了使用什么样的 exprs, 没太懂这一块设计?
初始化部分主要是 compile_expressions() 这个批量处理正则表达式的函数
批量处理正则表达式
SEPARATOR = re.compile(' *, *')
def compile_expressions(self, exprs):
self.expressions = []
for expr in SEPARATOR.split(str(exprs).strip()):
self.compile_expression(expr)
这里需要注意,正则匹配是 若干个空格+逗号+若干个空格,所以对于传入的 exprs,先通过 strip() 将首尾的空格去除后在进行匹配
这里的核心还是如何处理单个正则表达式 compile_expression()
处理单个正则表达式
def compile_expression(self, expr):
for compiler in self.COMPILERS:
match = compiler.value_re.match(expr)
if match:
compiled_expr = compiler(**match.groupdict())
try:
compiled_expr.validate_range(self.name)
except ValueError as e:
exc = ValueError('Error validating expression {!r}: {}'.format(expr, e))
six.raise_from(exc, None)
self.expressions.append(compiled_expr)
return
raise ValueError('Unrecognized expression "%s" for field "%s"' % (expr, self.name))
从这里可以看出从 COMPILERS = [AllExpression, RangeExpression] 依次取出对象,使用其中定义的 value_re 来解析表达式
如果,匹配 match 成功,则根据匹配的结果,初始化 Expression 对象,而这个对象提供了 get_next_value() 接口,最后在保存到 self.expressions 对象中
get_next_value()
def get_next_value(self, dateval):
smallest = None
for expr in self.expressions:
value = expr.get_next_value(dateval, self)
if smallest is None or (value is not None and value < smallest):
smallest = value
return smallest
前面提到 self.expressions 中保存了匹配成功后生成的对象,这里要做的,就是从这些对象中通过 get_next_value() 函数取出最小的值返回即可,也是没有什么难度的
其他子类
| 子类名称 | COMPILERS | 额外重载的函数 |
|---|---|---|
| BaseField | AllExpression, RangeExpression | get_value() |
| WeekField | AllExpression, RangeExpression | get_value() |
| DayOfWeekField | AllExpression, RangeExpression, WeekdayRangeExpression | get_value() |
| MonthField | AllExpression, RangeExpression, MonthRangeExpression | 无 |
| DayOfMonthField | AllExpression, RangeExpression, WeekdayPositionExpression, LastDayOfMonthExpression | get_max() |
简单总结了一下,可以看出子类主要是为了补充需要自己解释的正则表达式格式,现在只需要简单看一下这些额外重载的函数实现
# WeekField 的重载函数 get_value
def get_value(self, dateval):
return dateval.isocalendar()[1]
传入的参数是一个类型为 date 的时间, isocalendar() 函数是 datetime 下提供的函数,主要是返回这个 dateval 的年,第几周,周几这3个值
# DayOfMonthField 的重载函数 get_max()
def get_max(self, dateval):
return monthrange(dateval.year, dateval.month)[1]
上一篇文章介绍过 monthrange() 函数就是返回一个月第一天是周几(0-6), 以及这个月总的天数,而总的天数其实就是这个月天数的最大值
# DayOfWeekField 的重载函数 get_value()
def get_value(self, dateval):
return dateval.weekday()
weekday() 返回 dateval 是周几(0-6)
除此之外,还有一个需要特别注意的地方, BaseField 中默认定义的 REAL=True,但是在 WeekField 和 DayOfWeekField 被设置为 False
简单说一下我对这个字段的理解,在上层通过 BaseField 及其子类的 get_next_value() 获取到一个数值的时候,我们需要根据这个时间换算从一个新的时间,而 WeekField 多少周, DayOfWeekField 一周里的第几天这2个字段,并没有办法直接变成具体的日期,需要额外标识出这个字段是否能直接用,而这些字段具体如何用,在后文中会有介绍,先有个印象
CronTrigger
终于看到 CronTrigger 这个类了,这一部分的实现还是挺有意思的,首先类定义了支持处理的字段,以及这些字段对应用来封装的 BaseField 类或者子类的信息
FIELD_NAMES = ('year', 'month', 'day', 'week', 'day_of_week', 'hour', 'minute', 'second')
FIELDS_MAP = {
'year': BaseField,
'month': MonthField,
'week': WeekField,
'day': DayOfMonthField,
'day_of_week': DayOfWeekField,
'hour': BaseField,
'minute': BaseField,
'second': BaseField
}
结合前面的,列一个总的表格,详细看一下
| 字段 | 封装的类 | COMPILERS |
|---|---|---|
| year | BaseField | AllExpression (*/step,*)RangeExpression (first,first-last,first/step,first-last/step) |
| hour | BaseField | 同上 |
| minute | BaseField | 同上 |
| second | BaseField | 同上 |
| week | WeekField | 同上 |
| month | MonthField | AllExpression (*/step,*)RangeExpression (first,first-last,first/step,first-last/step)MonthRangeExpression (first,first-last)['jan', 'feb', 'mar', 'apr', 'may', 'jun', 'jul', 'aug', 'sep', 'oct', 'nov', 'dec'] |
| day | DayOfMonthField | AllExpression (*/step,*)RangeExpression (first,first-last,first/step,first-last/step)WeekdayPositionExpression (option_name weekday_name) LastDayOfMonthExpression (last) |
| day_of_week | DayOfWeekField | AllExpression (*/step,*)RangeExpression (first,first-last,first/step,first-last/step)WeekdayRangeExpression (first,first-last) ['mon', 'tue', 'wed', 'thu', 'fri', 'sat', 'sun'] |
初始化
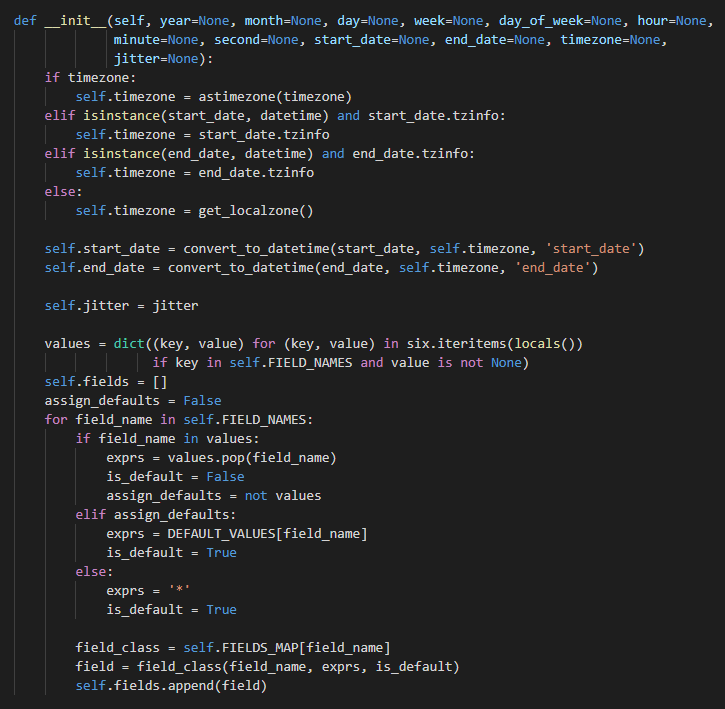
- 首先判断 时区,如果有设置,直接就用,否则根据 开始时间 或者 结束时间 中的时区来决定,都没有则使用 系统本地时区
- 使用
convert_to_datetime()函数格式化传入开始时间和结束时间,因为传入的可以不是datetime对象,可以只是字符串类型,需要转换成datetime类型 - 设置
jitter, 之前介绍的提前或延迟job执行的误差时间 - 整理所有值不为
None的字段且属于FIELD_NAMES中的字段, 并以(field, value)的形式存储到一个dict的values中 - 对所有需要设置的字段进行遍历,生成对应的类似于
BaseField的对象 - 最后将这些字段生成对象保存到
self.fields中
这里设置默认值的时候的设计其实还挺复杂, 第一种是 DEFAULT_VALUES 中默认值,第二种是 *
DEFAULT_VALUES = {'year': '*', 'month': 1, 'day': 1, 'week': '*', 'day_of_week': '*', 'hour': 0, 'minute': 0, 'second': 0}
首先需要对传入的默认值做一个区别的介绍
- 当
exprs是*的时候,基本是对应字段是什么值,get_next_value()的时候就会返回什么值 - 当
exprs是数值也就是DEFAULT_VALUES中的 0 或者 1 的时候,使用RangeExpression中的匹配规则,这里就是first类型,等于在这个字段整个范围内只会在 0 或者 1 的时候触发,如果所有字段都是first格式,那么就相当于是dateTrigger, 一个一次性执行的任务
FIELD_NAMES 是按照 year 到 second 的顺序一个一个在 values 中查找
- 如果
values中没有,但是values不为空 (每次匹配到,会从values中pop出来),则使用默认* - 如果
values中没有,并且values为空,则使用DEFAULT_VALUES的默认值
举个例子,解释一下这样设计的目的
trigger1 = CronTrigger(second='*/5')
trigger2 = CronTrigger(year='*', month='4', day='1')
trigger1 根据上面的初始化设计思路,其余字段都是 *, 因为 second 是 FIELD_NAMES 中最后一个字段,等于每隔 5 秒执行一次,因为你在这样定义的时候,更倾向于 second 的使用,而它前面时间字段是什么值是不关心,那么使用 * 是很合理的
trigger2 的意图是每年 4 月 1 号执行,根据初始化思路,从 day 之后的字段,也就是从 week 开始的字段的默认值都是 DEFAULT_VALUES 对应的字段,那么实际上 trigger2 实际上就是每年 4 月 1 号的 0 点 0 分 0 秒执行,既然你不设置,那就按照我的默认值设置,因为 CronTrigger 最后还是需要返回一个具体的时间
所以简单总结一下就是:
大于用户最小设置字段的未定义字段使用
*初始化,小于的则使用DEFAULT_VALUES中对应的值初始化,默认的DEFAULT_VALUES更倾向于具体的时间点
get_next_fire_time()
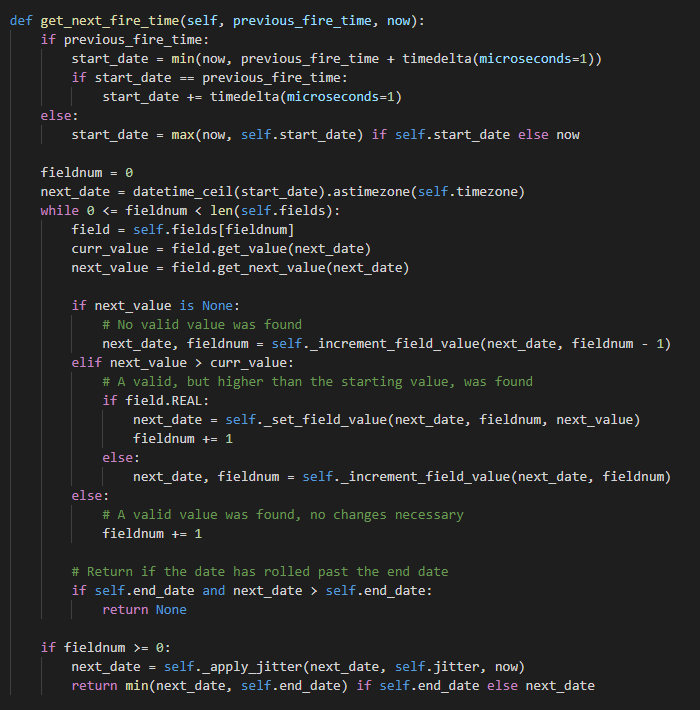
while 循环之前就是获取一个 start_date, 并根据 start_date 向上取整得到一个 next_date, 这个 next_date 是一个还没有到的时间,在这个时间基础上计算出下一次执行时间,这个还算合理,假设我设置 second='*' 其它字段默认,因为一个向上取整,这个向上取整只是在秒的位置上加 1,然后去掉秒后面的数字,等于 1 秒执行一次,这种设计是可以接受的,但是记住,这个取整在之后会有一个大坑~
之后的 while 循环中需要注意一点,CronTrigger 本质上还是需要获取下次执行时间,只是它是通过获取每个时间字段的下次执行的时间,但是涉及到正则表达式解析的 AllExpression 等类的 get_next_value() 函数是会返回 None 的,这里我们就需要对返回 None 进行判断,而这里就是 CronTrigger 最复杂的地方了
if next_value is None:
next_date, fieldnum = self._increment_field_value(next_date, fieldnum - 1)
这里还是需要先研究一下 _increment_field_value() 这个函数
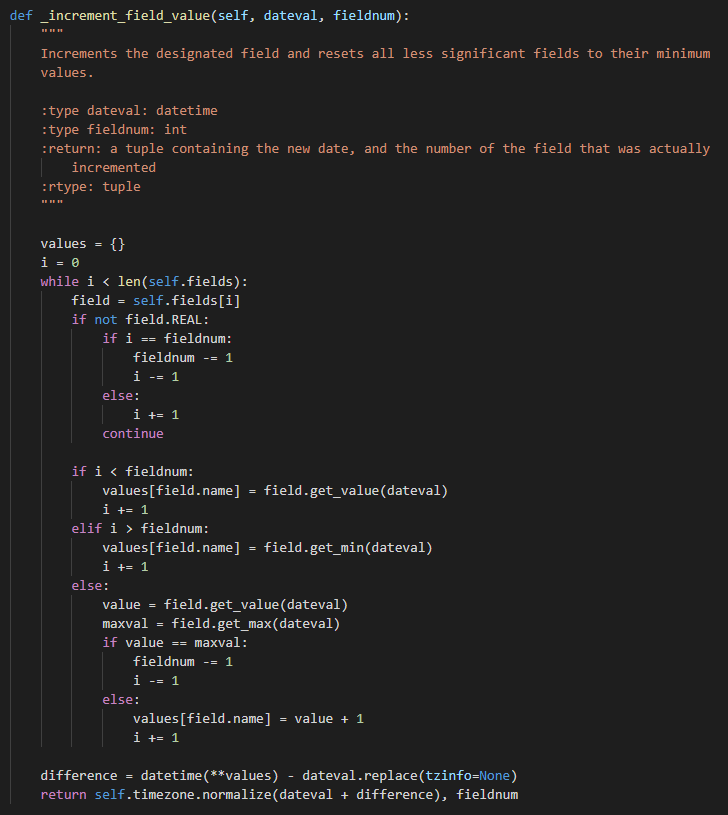
这个函数有一段英文解释,大致意思就是:递增指定字段,并将所有不重要的字段重置为其最小值(谷歌翻译)。
首先需要知道一点,这个函数是干啥的? 这个函数的目的就是,当我某一个字段获取到的值为 None 的时候,这意味着这个时间是无效的,我需要重新算出一个新的 next_date,新的 next_date 的实现就全靠这个函数,先举个例子,再来解释具体实现逻辑
trigger = CronTrigger(year='*', month='4', day='1')
定义的 CronTrigger 目标是每年的 4 月 1 号执行一次, 现在演示一下 while 中的部分逻辑,不明白 next_value 的值为什么是这个的,建议看一下我上一篇总结
- 假设现在的时间是
2021-04-10 22:35:10,year的next_value的值为2021,month的next_value的值为4, 但是day因为目标是1, 但是当前时间是10, 所以next_value返回的是None, 这时候就会调用_increment_field_value()函数, 得到一个新的时间2021-05-01 00:00:00的时间 - 现在的时间是
2021-05-01 00:00:00,year的next_value的值为2021,month的next_value的值为None, 继续调用_increment_field_value()函数,得到一个新的时间2022-01-01 00:00:00 - 现在的时间是
2022-01-01 00:00:00,经过一轮判断最后可以得到一个新的执行时间2022-04-01 00:00:00
返回 None 的意思就是在当前自己的最大值最小值范围内并没有合适值,那么就需要将它前一位字段加一,然后重新找是否有合适的值,等于是扩大一个范围。所以从例子中可以看出 2021-04-10 中寻找 4 月 1 号,没有找到,然后从向前一位到 2021-05 中找,先验证月份,发现 2021-05 中找不到 4 月,那就在向前一位到 2022 年中找先验证 year,接着是 month、day 等等,最后找到 2022-04-01 00:00:00
和它的英文解释一样,将 fieldnum 位置的字段递增加一 (加一的时候确保没有超出这个字段的最大值),这个字段之后的字段 (i > fieldnum) 直接设置成最小值,小于前一个字段的 (i < fieldnum) 值不变
所以结合 next_value 为 None, 那么就需要将为 None 字段的前一个字段位置传入 _increment_field_value() 即可,重新计算一个新的 next_date,直到找到一个合适的 next_date
为 None 的判断算是结束了,现在接着看后面 next_value > curr_value
elif next_value > curr_value:
if field.REAL:
next_date = self._set_field_value(next_date, fieldnum, next_value)
fieldnum += 1
else:
next_date, fieldnum = self._increment_field_value(next_date, fieldnum)
前面其实介绍了 field.REAL 这个字段的意义,除了 WeekField 和 DayOfWeekField 分别对应 week (第多少周) 和 day_of_week (一周内的周几) 这2个字段(field.REAL=False),其他字段都是 datetime 对象中成员变量,直接设置,就能更新 next_date, 所以还会需要先看一下 _set_field_value() 函数
def _set_field_value(self, dateval, fieldnum, new_value):
values = {}
for i, field in enumerate(self.fields):
if field.REAL:
if i < fieldnum:
values[field.name] = field.get_value(dateval)
elif i > fieldnum:
values[field.name] = field.get_min(dateval)
else:
values[field.name] = new_value
return self.timezone.localize(datetime(**values))
fieldnum位置的字段设置成新的值new_value,fieldnum位置之前的字段不变,之后的字段取最小值
那现在就有一个问题了 week 和 day_of_week 这 2 个 field.REAL=False 的判断怎么办?
源码中的做法是通过 _increment_field_value() 重新计算 next_date, 直到出现 next_value 等于 curr_value 这种情况,给我的感觉就是一种拿当前的时间一直递增去试错的感觉,不匹配, 在 day 递增 1 天,继续判断,直到值相等
那什么时候停止呢?当 0 <= fieldnum < len(self.fields), 这里存在 2 种可能
- 第一种大于
len(self.fields), 这时候等于对每个字段都做了设定,得到一个合适的next_date - 第二种小于
0, 这时候是没有找到合适next_date
当然最后还需要将 fieldnum 的值与 self.end_date 做一次大小的判断,正确返回 next_date 即可
序列化和反序列化
这一部分很简单,就不额外解释了~
from_crontab()
一个 classmethod 的函数,虽然不太清楚这个函数具体的用法,但是看实现,就是通过 expr 来初始化一个 CronTrigger
expr 中有5个字段,按照空格隔开,依次分别是 minute, hour, day, month, day_of_week
@classmethod
def from_crontab(cls, expr, timezone=None):
values = expr.split()
if len(values) != 5:
raise ValueError('Wrong number of fields; got {}, expected 5'.format(len(values)))
return cls(minute=values[0], hour=values[1], day=values[2], month=values[3],
day_of_week=values[4], timezone=timezone)
总结
整个 CronTrigger 对源码的解析就这样结束了,分析完之后,对 CronTrigger 有了一个新的理解,和 DateTrigger 和 IntervalTrigger 一样本质都是返回一个下一次执行的时间
但是 CronTrigger 是针对时间的每一字段做了定制化的设置,当某一个字段通过 get_next_value() 获取值为 None 的时候,让这个字段的前一个字段 x 自增, x 前的字段值不变,x 后的字段全部置为最小值,从而得到获取一个新的 next_date ,然后重复 get_next_value() 这样的操作,直到遍历完所有的字段,或者连第一个 year 字段都返回 None 时停止
这样的思路还是挺有意思的~