趁热打铁,学习一下 APScheduler 的 python 的源码,很好奇任务调度控制的实现。
分析源码主要还是针对 APScheduler 下的几个关键的模块
events事件executors执行器job任务jobstores任务存储triggers触发器schedulers调度程序
这一篇主要瞅瞅 jobstores 事件
总览
定义一个基类 base.py, 基类中可能包含对添加任务,删除任务等等接口,不同的 任务存储 (memory, mongodb, redis 等等) 在实现基类定义的虚函数
首先 base.py 定义了一些自己的一些异常类
JobLookupError: 当更新或者删除一个任务时,不能在任务存储中找到时 触发ConflictingIdError:在 违反任务 ID 的唯一性 时触发。TransientJobError:检测到试图向 持久化的任务存储 添加的临时任务 不带 func_ref 时触发。如果看过前面关于job的介绍,job会对func做一个序列化的过程,而这个过程对一些例如partial等的函数是存在序列化失败的问题
而最后一个 BaseJobStore 定义了所有任务存储公共的函数,接下来主要就是看一下这个类
BaseJobStore
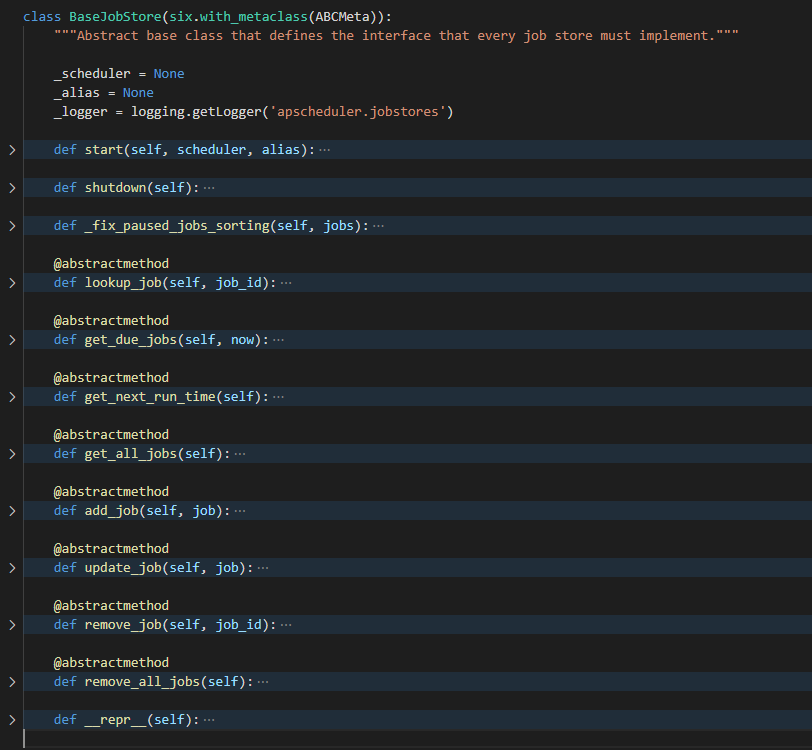
其实仔细看, BaseJobStore 除了
start(): 启动调度程序或任务存储时由调度程序 (scheduler) 调用,添加到已经运行的调度程序中shutdown(): 释放仍绑定到此作业存储库的所有资源_fix_pause_jobs_sorting(): 对获取的任务列表进行排序,暂停的任务会被排到最后
其它函数全是虚函数,交给子类自由实现
lookup_job: 根据 任务ID 返回任务,如果没有找到,则返回Noneget_due_jobs: 返回将要执行的任务列表,也就是任务下次执行时间(next_run_time) 比当前时间早或相等get_next_run_time:返回任务存储中所有任务的最早执行时间,如果返回None, 代表任务存储中没有活跃任务get_all_jobs: 返回任务存储中所有的任务add_job: 向任务存储中添加任务update_job: 更新任务存储中的指定任务remove_job: 根据 任务ID 删除任务存储中的指定任务remove_all_jobs:删除任务存储中的所有任务
看到这里,我们知道 BaseJobStore 主要就是定义好提供的接口,交由子类自己实现,接下来我们选择 2 个子类,着重看一下它们的具体实现代码 MemoryJobStore, RedisJobStore
MemoryJobStore
MemoryJobStore 是将任务存储在内存中,所以不提供持久化支持。它的实现相对简单, 主要就是如何管理 Job
def __init__(self):
super(MemoryJobStore, self).__init__()
self._jobs = []
self._jobs_index = {}
- 使用
(list) self._jobs来保存一个(job,timestamp)的列表, 并且按照timestamp也就是任务下次运行时间做一个升序的排列 - 为了方便检索,
(dict) self._jobs_index创建一个job.id和(job,timestamp)一一对应的字典
因为维护的是一个排好序的任务队列 self._jobs,所以
- 获取任务存储中所有任务的接口
get_all_jobs()很简单 - 获取任务存储中所有任务的最早执行时间的接口
get_next_run_time()很简单 - 获取执行时间不为
None或大于等于当前时间任务的任务队列的接口get_due_jobs()也很简单
因为维护了根据任务ID job.id 建立索引的字典 self._jobs_index
- 根据
job.id查找job的接口lookup_job()很简单 - 根据
job.id删除job的接口remove_job()很简单
那么剩下来最麻烦的部分就是如何维护一个升序的 self._jobs 队列, 以及在 删除、修改 job 的时候同步修改 self._jobs 和 self._jobs_index 这2个对象中的 job
以 add_job() 函数为例
def add_job(self, job):
if job.id in self._jobs_index:
raise ConflictingIdError(job.id)
timestamp = datetime_to_utc_timestamp(job.next_run_time)
index = self._get_job_index(timestamp, job.id)
self._jobs.insert(index, (job, timestamp))
self._jobs_index[job.id] = (job, timestamp)
- 首先判断需要被添加的
job的id是否已经存在,存在的话,直接抛出ConflictingIdError异常 - 将任务下次执行的时间转换成时间戳,方便排列比较
_get_job_index()函数来定位出这个任务应该在队列中的位置- 最后将需要被添加的
job保存到self._jobs和self._jobs_index中
所以接下来主要看一下 _get_job_index 函数
def _get_job_index(self, timestamp, job_id):
lo, hi = 0, len(self._jobs)
timestamp = float('inf') if timestamp is None else timestamp
while lo < hi:
mid = (lo + hi) // 2
mid_job, mid_timestamp = self._jobs[mid]
mid_timestamp = float('inf') if mid_timestamp is None else mid_timestamp
if mid_timestamp > timestamp:
hi = mid
elif mid_timestamp < timestamp:
lo = mid + 1
elif mid_job.id > job_id:
hi = mid
elif mid_job.id < job_id:
lo = mid + 1
else:
return mid
return lo
仔细一看,就是一个很标准的 二分查找,但是这里有个比较特殊的地方——对 job_id 的比较
这个主要是因为,可能现在任务的队列中存在暂停的计划,暂停的计划的 timestamp 是 None, 举个更详细的例子
当我暂停一个计划的时候,我需要先调用
job的_modify()函数,将job的next_run_time置为None,然后调用jobstore的update()函数
def update_job(self, job):
old_job, old_timestamp = self._jobs_index.get(job.id, (None, None))
if old_job is None:
raise JobLookupError(job.id)
old_index = self._get_job_index(old_timestamp, old_job.id)
new_timestamp = datetime_to_utc_timestamp(job.next_run_time)
if old_timestamp == new_timestamp:
self._jobs[old_index] = (job, new_timestamp)
else:
del self._jobs[old_index]
new_index = self._get_job_index(new_timestamp, job.id)
self._jobs.insert(new_index, (job, new_timestamp))
self._jobs_index[old_job.id] = (job, new_timestamp)
- 根据
job.id找到旧的计划 - 因为我们是按照
timestamp进行排序的,所以查看旧的job的执行时间和新的job执行时间是否一样- 一样,直接更新
self._jobs中保存的job即可 - 不一样,删除旧的
job,重新定位位置,更新到self._jobs中
- 一样,直接更新
- 最后更新
self._jobs_index即可
在暂停计划这种情况下,当队列中已经存在暂停的计划时,也就是 timestamp (next_run_time) 为 None 时,就需要再按照 job_id 的字符串大小来进行排序
基于内存的 MemoryJobStore 的整体看出来,需要注意的只有一个 _get_job_index() 二分查找~
RedisJobStore
RedisJobStore 通过将任务存储到 redis 数据库中,从而支持任务的持有化功能,但是它的核心还是和MemoryJobStore 一样,实现基类的提供的虚函数,我们主要就是了解它是如何管理在 redis 中管理任务
重温一下 MemoryJobStore
- 使用
(list) self._jobs来保存一个(job,timestamp)的列表,这个主要维护任务存储中各个任务的执行时间,并且按照执行时间从近到远排序 - 使用
(dict) self._jobs_index创建一个job.id和(job,timestamp)一一对应的字典,方便检索
MemoryJobStore 的思路基本是一样的
- 使用
zset来保存一个job.id和它下次执行时间的job.next_run_time的有序集合 - 使用
hash创建一个job.id和Job的序列化数据一一对应的哈希表
简单介绍一下 redis 下这两种数据类型
zset有序集合
zset是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis通过分数来为集合中的成员进行从小到大的排序。
刚好我们需要按时间顺序给job排序,所以zset真的特别合适hash哈希
是一个键值对集合,特别适合用于存储对象
保存任务的成员类型确定了,那么接下来就是看主要的函数实现
初始化
def __init__(self, db=0, jobs_key='apscheduler.jobs', run_times_key='apscheduler.run_times',
pickle_protocol=pickle.HIGHEST_PROTOCOL, **connect_args):
super(RedisJobStore, self).__init__()
if db is None:
raise ValueError('The "db" parameter must not be empty')
if not jobs_key:
raise ValueError('The "jobs_key" parameter must not be empty')
if not run_times_key:
raise ValueError('The "run_times_key" parameter must not be empty')
self.pickle_protocol = pickle_protocol
self.jobs_key = jobs_key
self.run_times_key = run_times_key
self.redis = Redis(db=int(db), **connect_args)
说明一下
db: 使用的redis的哪一个数据库,这个是与redis连接时需要使用的一个变量,默认为0jobs_key: 是hash的键名称run_times_key: 是zset的键名称pickle_protocol: 这个字段主要是当我们将Job序列化时使用的协议connect_args: 连接redis时,需要的配置参数,比如redis的ip,port,password等等
函数体剩下就是对成员变量赋值,以及连接 redis, 这里使用的是 redis 的 StrictRedis 方式
add_job
def add_job(self, job):
if self.redis.hexists(self.jobs_key, job.id):
raise ConflictingIdError(job.id)
with self.redis.pipeline() as pipe:
pipe.multi()
pipe.hset(self.jobs_key, job.id, pickle.dumps(job.__getstate__(),
self.pickle_protocol))
if job.next_run_time:
pipe.zadd(self.run_times_key,
{job.id: datetime_to_utc_timestamp(job.next_run_time)})
pipe.execute()
- 首先查看
hash中是否已经存在hexists重复的job.id, 如果存在直接抛出ConflictingIdError的异常 - 使用
redis管道操作,一方面可以一次发送多条命令,一次收到所有处理结果,很大程度上提高处理的效率,另一方支持事务,事务中的命令要么全部被执行,要么全部都不执行。hash和zset要么都成功执行,要么都回滚- 创建一个事务
- 向
hash中存入job.id以及job的序列化数据 - 向
zset中存入job.id和next_run_time的集合 - 提交事务
不过这里有个细节,如果任务存在 job.next_run_time 时,才会被放到 zset 中
此外,如果看过我之前关于 job 介绍的时候,job 中存在 self.func_ref, 通过 obj_to_ref() 函数将任务函数序列化成字符串,所以这里需要保证函数本身支持序列化,至于不支持的有哪些,可以在看一下之前的文章~
update_job
在了解了 add_job 之后,更新其实没什么难度了,不过这里有个细节,既然是更新,说明任务在 redis 中一定要存在
- 先在
hash中找一下任务,如果不存在,抛出JobLookupError找不到任务的异常 - 剩下的和添加基本一样,不过多了一个判断,当
job.next_run_time不存在,也就是None的时候,需要删除zset中保存的job.id
def update_job(self, job):
if not self.redis.hexists(self.jobs_key, job.id):
raise JobLookupError(job.id)
with self.redis.pipeline() as pipe:
pipe.hset(self.jobs_key, job.id, pickle.dumps(job.__getstate__(),
self.pickle_protocol))
if job.next_run_time:
pipe.zadd(self.run_times_key,
{job.id: datetime_to_utc_timestamp(job.next_run_time)})
else:
pipe.zrem(self.run_times_key, job.id)
pipe.execute()
remove_job
- 判断
hash中是否存在这个任务,如果不存在,抛出JobLookupError找不到任务的异常 - 使用
hdel函数删除hash中指定的job.id - 使用
zrem函数删除zset中指定的job.id
remove_all_jobs
整个清空,redis 直接删除 self.jobs_key 和 self.run_times_key 即可
lookup_job
使用 redis 中的 hget 命令从 hash 中根据 job_id 查找
def lookup_job(self, job_id):
job_state = self.redis.hget(self.jobs_key, job_id)
return self._reconstitute_job(job_state) if job_state else None
这里出现了一个新的函数 _reconstitute_job(), 可以简单看一下这个函数
def _reconstitute_job(self, job_state):
job_state = pickle.loads(job_state)
job = Job.__new__(Job)
job.__setstate__(job_state)
job._scheduler = self._scheduler
job._jobstore_alias = self._alias
return job
它的核心就是将从 redis 中存储的 job 序列化信息反序列化后,传入 Job 中,得到一个 job 对象
get_next_run_time
使用 redis 中的 zrange 命令从 zset 中找到一个最小的执行日期 next_run_time
def get_next_run_time(self):
next_run_time = self.redis.zrange(self.run_times_key, 0, 0, withscores=True)
if next_run_time:
return utc_timestamp_to_datetime(next_run_time[0][1])
函数默认返回 None, 所以没有把 if...else... 写全也行吧
return utc_timestamp_to_datetime(next_run_time[0][1]) if next_run_time else None
get_due_jobs
def get_due_jobs(self, now):
timestamp = datetime_to_utc_timestamp(now)
job_ids = self.redis.zrangebyscore(self.run_times_key, 0, timestamp)
if job_ids:
job_states = self.redis.hmget(self.jobs_key, *job_ids)
return self._reconstitute_jobs(six.moves.zip(job_ids, job_states))
return []
- 从
szet中找出下次执行时间大于等于当前时间的job_ids - 在根据
job_ids从hash中找到对应的job序列化数据,并通过_reconstitute_jobs()返回
前面看了 _reconstitute_job() 函数,这里的 _reconstitute_jobs() 就是通过 _reconstitute_job() 函数对一个 list 进行处理
zip()函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
get_all_jobs
def get_all_jobs(self):
job_states = self.redis.hgetall(self.jobs_key)
jobs = self._reconstitute_jobs(six.iteritems(job_states))
paused_sort_key = datetime(9999, 12, 31, tzinfo=utc)
return sorted(jobs, key=lambda job: job.next_run_time or paused_sort_key)
- 通过
hgetall从hash中获取所有的任务 - 通过
_reconstitute_jobs将这些任务转换成job对象的列表 - 然后根据
job的next_run_time将job进行排序
关于 MemoryJobStore 中涉及到所有接口基本上都详细的介绍了一遍
总结
关于 BaseJobStore 下其实还有 MongoDBJobStore ,RethinkDBJobStore 等等其他支持持久化的子类,整体其实都大同小异
JobStore 核心就是如何维护好一个以 job.next_run_time 大小为标准排好序的列表以及如何保存所有任务以便于检索~