我们开发时使用频率还挺低,但广泛运用于编译器的一种设计模式~
意图
给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子
什么 文法,建议看一下这篇 blog, https://blog.csdn.net/qq_40147863/article/details/88770715
文法 引出2个新的概念:终结符 和 非终结符
终结符是一个形式语言的基本符号。就是说,它们能在一个形式语法的推导规则的输入或输出字符串存在,而且它们不能被分解成更小的单位。确切地说,一个语法的规则不能改变终结符。- 不是
终结符的都是非终结符。非终结符可理解为一个可拆分元素,而终结符是不可拆分的最小元素。
动机
如果一种特定类型的问题发生的频率足够高,那么可能就值得将该问题的各个实例表述为一个简单语言中的句子。这样就可以构建一个解释器,该解释器通过解释这些句子来解决该问题。
举个简单例子,正则表达式,一种描述字符串模式的标准语言,它就是使用一种通用的搜索算法来解释执行一个正则表达式,该正则表达式定义了待匹配字符串的集合。
UML 图
光看 UML 其实很懵,建议配合后文中的例子享用
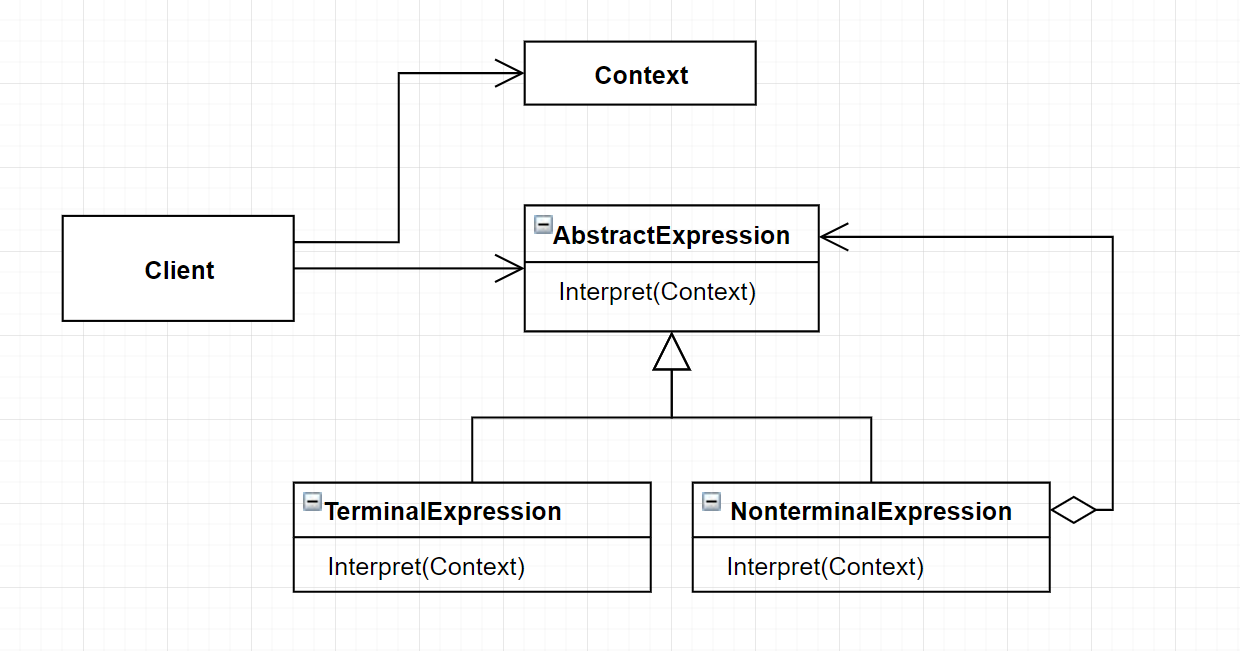
AbstractExpression: 抽象解释器
声明一个抽象的解释操作,这个接口为抽象语法树中的所有节点所共享TerminalExpression: 终结符解释器
实现与文法中的终结符相关联的解释操作
一个句子中的每个终结符需要该类的一个实例NonterminalExpression: 非终结符解释器
为文法中的非终结符实现解释操作 对文法中的每条规则都需要一个NonterminalExpression类Context
包含解释之外的一些全局信息Client
调用解释操作,并构建或被给定表示该文法定义的语言中一个特定的句子的抽象语法树,该抽象语法树由TerminalExpression和NonterminalExpression的实例装配而成
优缺点
优点
- 易于改变和扩展文法
- 也易于实现文法
缺点
- 执行效率低,因为通常使用大量的循环和递归调用,当句子比较复杂的时候,不管是调试还是运行效果可能都不太好
- 复杂的文法难以维护,文法中每一条规则至少定义一个类,包含许多规则的文法可能难以管理和维护
应用场景
当有一个语言需要解释执行,并且你可将该语言中的句子表示为一个抽象语法树时,可使用解释器模式,但是文法要相对简单,对于复杂的文法,文法的类层次变得庞大而无法管理
举个例子
结合 《大话设计模式》 中关于数字简谱解释器的例子,我稍微改动一下,以便更好理解
定义一个文法规则
<expression> ::= <音阶> <音符> //表达式,二者使用空格隔开
composite ::= expression | expression //复合表达式
<音阶> ::= 1 | 2 | 3 | 4 | 5 | 6 | 7
<音符> ::= 一个 double 类型
简单解释一下,我们使用 1 1 | 3 1/8 | 4 1/2 这种形式表示乐谱,其中 1 2 3 4 5 6 7 分别对应 Do Re Mi Fa Sol La Xi, 音阶后面跟着用来记录不同长短的音的进行符号–音符, 1 1/2 1/4 1/8 分别对应 全音符 二分音符 四分音符 八分音符
接下来我们的目标就是把数字简谱 1 1 | 3 1/8 | 4 1/2 转换成 Do 全音符 Mi 八分音符 Fa 二分音符
代码我可能更简单一点,首先定义一个 AbstractExpression,其实没啥东西,就是定义了一个解析的接口
class AbstractExpression
{
public:
virtual ~AbstractExpression() {}
virtual string Interpret(string context) = 0;
};
接着定义音阶的解释器,主要负责把 1 2 3 4 5 6 7 解释为 Do Re Mi Fa Sol La Xi
class Scale_NonTerminalExpression : public AbstractExpression
{
public:
virtual string Interpret(string context) {
if ( context == "1")
return "Do";
else if ( context == "2")
return "Re";
else if ( context == "3")
return "Mi";
else if ( context == "4")
return "Fa";
else if ( context == "5")
return "Sol";
else if ( context == "6")
return "La";
else
return "Xi";
}
};
然后定义音符解释器,负责把 1 1/2 1/4 1/8 解释为 全音符 二分音符 四分音符 八分音符
class Note_NonTerminalExpression : public AbstractExpression
{
public:
virtual string Interpret(string context) {
if ( context == "1")
return "全音符";
else if ( context == "1/2")
return "二分音符";
else if ( context == "1/4")
return "四分音符";
else
return "八分音符";
}
};
我们这里其实有两个 非终结符 的表达式, 分别为形为 <expression> ::= <音阶> <音符> 以及一个复合表达式
第一种主要是有 音阶终结符 和 音符终结符 二者通过空格连接起来了,是我们定义的规则,先实现这种方式
class TerminalExpression : public AbstractExpression {
public:
TerminalExpression() : m_scale(new Scale_NonTerminalExpression), m_note(new Note_NonTerminalExpression) {}
~TerminalExpression() { SAFE_DELETE(m_scale); SAFE_DELETE(m_note); }
virtual string Interpret(string context) {
list<string> split_result = split(context," ");
if (split_result.size() != 2) return "";
string scale = m_scale->Interpret(split_result.front());
string note = m_note->Interpret(split_result.back()) ;
return scale + " " + note;
}
private:
Scale_NonTerminalExpression * m_scale;
Note_NonTerminalExpression * m_note;
};
通过 split() 函数切割表达式,然后分别用 m_scale 和 m_note 解释, 因为纯粹的 C++ 并没有直接的 split() 函数, 直接从网上找了一个简单的实现
list<string> split(const string& str, const string& pattern)
{
list<string> ret;
if (pattern.empty()) return ret;
size_t start=0,index=str.find_first_of(pattern,0);
while(index!=str.npos)
{
if(start!=index)
ret.push_back(str.substr(start,index-start));
start=index+1;
index=str.find_first_of(pattern,start);
}
if(!str.substr(start).empty())
ret.push_back(str.substr(start));
return ret;
}
复合表达式,实际上就是在表达式的基础上,额外做了一次 | 的切割,我就不单独实现一个类了,而是直接放在 main() 函数中了
#include "abstractexpression.h"
int main()
{
TerminalExpression a;
string context = "1 1 | 3 1/8 | 4 1/2";
list<string> split_result = split(context, "|");
for ( auto text : split_result)
cout << a.Interpret(text) << " ";
return 0;
}
输出结果:
Do 全音符 Mi 八分音符 Fa 二分音符
每一条文法规则都可以表示为一个类,如果要添加新的规则,只需要添加一个新的类就可以了
总结
解释器模式描述了如何为简单的语言定义一个文法,如何在该语言中表示一个句子,以及如何解释这些句子
日常使用频率很低很低,感觉理解了就好~