趁热打铁,学习一下 APScheduler 的 python 的源码,很好奇任务调度控制的实现。
分析源码主要还是针对 APScheduler 下的几个关键的模块
events事件executors执行器job任务jobstores任务存储triggers触发器schedulers调度程序
这一篇主要瞅瞅 events 事件 和 executors 执行器
events 事件
event 主要是 APScheduler 中触发的事件类,我们可以通过 add_listener() 为调度程序绑定监听函数,在收到指定事件后做一些自定义的操作
events 事件主要是根据事件的类型,进行封装的,什么意思呢?
比如调度程序启动关闭等事件封装成一个 SchedulerEvent 类,任务执行结果封装成一个 JobExecutionEvent 类等
因此 evnets 最后划分出 4 个类,代码很简单,主要就是使用类来区分用户关心的信息,不同的类中封装的信息不同,而具体的划分细节,可以看一下前一篇,有很详细的介绍
# 基类,任务调度过程时出现事件,例如调度程序启动 ,调度程序关闭等等
class SchedulerEvent(object):
def __init__(self, code, alias=None):
super(SchedulerEvent, self).__init__()
self.code = code
self.alias = alias
def __repr__(self):
return '<%s (code=%d)>' % (self.__class__.__name__, self.code)
# 涉及到任务和任务存储操作时的事件,例如任务添加到任务存储中,从任务存储中删除了任务 等
class JobEvent(SchedulerEvent):
def __init__(self, code, job_id, jobstore):
super(JobEvent, self).__init__(code)
self.code = code
self.job_id = job_id
self.jobstore = jobstore
# 涉及到将任务放到执行器时的事件,例如任务已经提交到执行器中执行,任务因为达到最大并发执行时,触发的事件
class JobSubmissionEvent(JobEvent):
def __init__(self, code, job_id, jobstore, scheduled_run_times):
super(JobSubmissionEvent, self).__init__(code, job_id, jobstore)
self.scheduled_run_times = scheduled_run_times
# 涉及到任务执行结果的事件, 例如任务被成功执行,任务在执行期间引发异常
class JobExecutionEvent(JobEvent):
def __init__(self, code, job_id, jobstore, scheduled_run_time, retval=None, exception=None,
traceback=None):
super(JobExecutionEvent, self).__init__(code, job_id, jobstore)
self.scheduled_run_time = scheduled_run_time
self.retval = retval
self.exception = exception
self.traceback = traceback
执行器的 UML 图
首先针对它涉及到的类画一个简单 UML 图,大致了解代码的层级关系
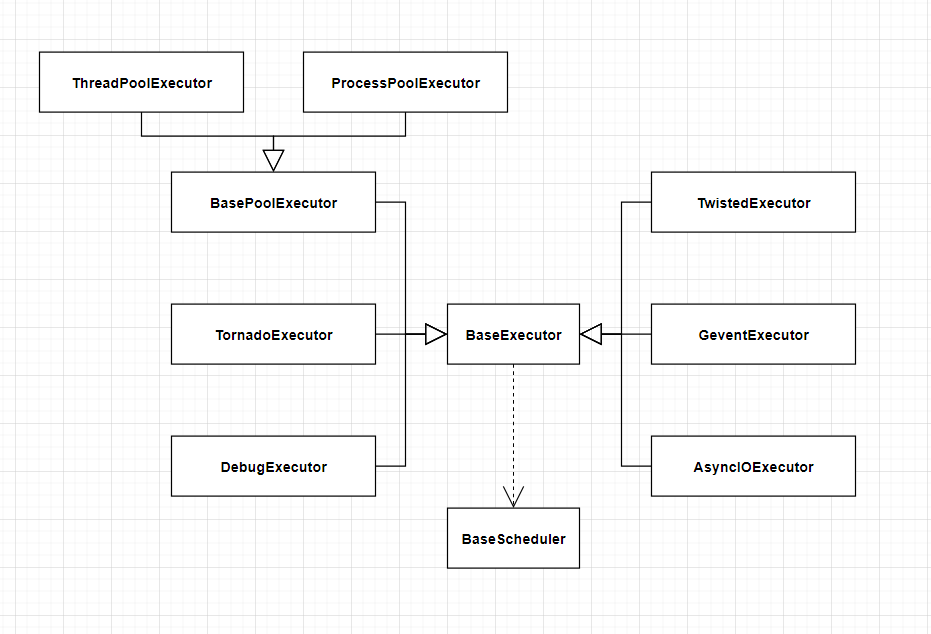
现在在整体看一下 BaseExecutor 代码的逻辑
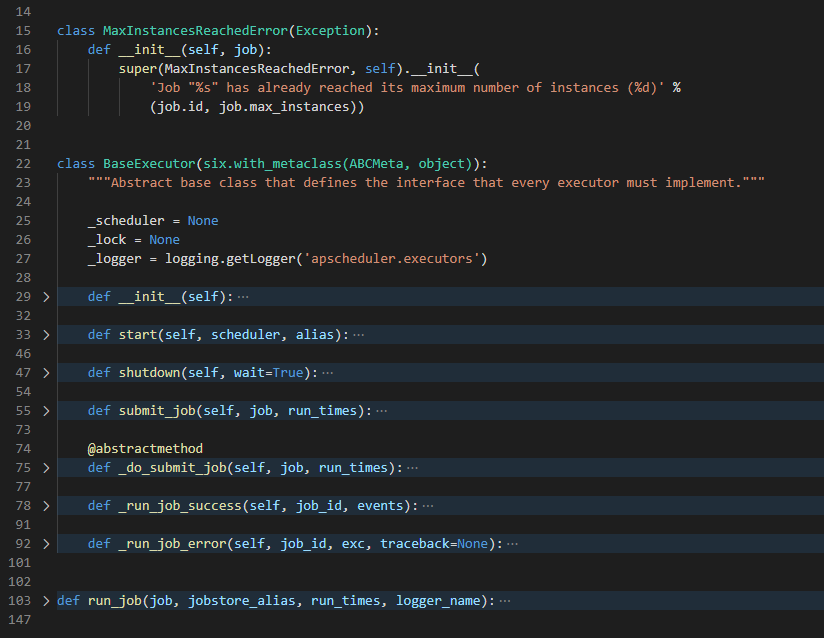
异常类
一个继承自 Exception 的自定义异常 MaxInstancesReachedError
class MaxInstancesReachedError(Exception):
def __init__(self, job):
super(MaxInstancesReachedError, self).__init__(
'Job "%s" has already reached its maximum number of instances (%d)' %
(job.id, job.max_instances))
初始化 __init__
def __init__(self):
super(BaseExecutor, self).__init__()
self._instances = defaultdict(lambda: 0)
super() 方法设计目的是用来解决多重继承时父类的查找问题,在涉及到子类中需要调用父类的方法时,这是个很好的习惯
self._instances 类型是 dict 字典类型, 主要是为了统计 job 同时运行的实例数,以 job.id 作为 key,同时运行的实例数作为对应的 value,主要是实现前面2篇提到过,我们是可以限制一个任务同时运行的最大实例数的 max_instances
这里的 defaultdict 就是一个关于初始化字典的小技巧,一般情况下,看一下下面这段代码:
# 初始化
dict={}
# 设置值
dict[element] = value
# 获取值
target = dict[element]
获取值的前提是 element 在字典中,如果不在字典里就会报错
通过 defaultdict(lambda: 0) 来保证当从 self._instances 取值的时候,如果不存在的时候,返回 0,而不会报错
启动 start
def start(self, scheduler, alias):
self._scheduler = scheduler
self._lock = scheduler._create_lock()
self._logger = logging.getLogger('apscheduler.executors.%s' % alias)
持有一个 BaseScheduler 对象主要是为了在任务执行成功失败后,可以将任务执行状态返回给调度程序 (因为调度程序支持用户对事件添加侦听器的功能)
初始化完成,再调用启动后,接下来主要看一下如何让 BaseScheduler 执行任务
提交任务 submit_job
def submit_job(self, job, run_times):
assert self._lock is not None,
with self._lock:
if self._instances[job.id] >= job.max_instances:
raise MaxInstancesReachedError(job)
self._do_submit_job(job, run_times)
self._instances[job.id] += 1
assert是为了确保BaseScheduler已经通过start()完成了部分成员变量的初始化- 在加锁的情况下,通过
self._instances获取正在运行的任务的实例,如果超过max_instances(默认为1), 则会抛出MaxInstancesReachedError的异常 self._do_submit_job()来真正执行这个任务- 正在运行的任务计数加
1
子类重载函数
因为执行器的不同,这里的 _do_submit_job() 是一个纯虚函数,需要子类自己实现
当然,shutdown(self, wait=True) 也交给子类实现,但是父类提供了一个缺省的实现
操作执行结果
_run_job_success(self, job_id, events)子类在任务执行成功后调用_run_job_error(self, job_id, exc, traceback=None)任务失败后调用
简单看一下实现,任务执行成功后,在加锁的前提下将任务计数减取 1, 如果为 0,则删除这个键值,最后将处理的事件,返回给 scheduler,执行失败也差不多,只是最后返回给 scheduler 包含更多的错误信息
def _run_job_success(self, job_id, events):
with self._lock:
self._instances[job_id] -= 1
if self._instances[job_id] == 0:
del self._instances[job_id]
for event in events:
self._scheduler._dispatch_event(event)
BaseScheduler 类里的部分都分析完了,还有一个 run_job(job, jobstore_alias, run_times, logger_name) 的函数
run_job
这个函数实现了任务的执行,并根据任务执行的结果,做相应信息的收集,是整个执行器里,最核心的部分
def run_job(job, jobstore_alias, run_times, logger_name):
events = []
logger = logging.getLogger(logger_name)
for run_time in run_times:
if job.misfire_grace_time is not None:
difference = datetime.now(utc) - run_time
grace_time = timedelta(seconds=job.misfire_grace_time)
if difference > grace_time:
events.append(JobExecutionEvent(EVENT_JOB_MISSED, job.id, jobstore_alias,
run_time))
logger.warning('Run time of job "%s" was missed by %s', job, difference)
continue
logger.info('Running job "%s" (scheduled at %s)', job, run_time)
try:
retval = job.func(*job.args, **job.kwargs)
except BaseException:
exc, tb = sys.exc_info()[1:]
formatted_tb = ''.join(format_tb(tb))
events.append(JobExecutionEvent(EVENT_JOB_ERROR, job.id, jobstore_alias, run_time,
exception=exc, traceback=formatted_tb))
logger.exception('Job "%s" raised an exception', job)
if six.PY2:
sys.exc_clear()
del tb
else:
import traceback
traceback.clear_frames(tb)
del tb
else:
events.append(JobExecutionEvent(EVENT_JOB_EXECUTED, job.id, jobstore_alias, run_time,
retval=retval))
logger.info('Job "%s" executed successfully', job)
return events
大致处理的逻辑是这样的:
- 调度程序调用
run_job(),携带参数任务和任务所属的任务存储别名,执行时间和日志logger_name - 当任务配置了
misfire_grace_time,这个字段指的是当真正执行任务的时间与计划执行时间的误差,也就是在设置的误差范围内,任务被调用时,该任务还是会被执行,反之则任务状态就会为EVENTJOBMISSED,不执行 try里执行预定的任务- 然后对执行结果状态按照成功失败分别处理
- 成功,直接将事件状态设置成
EVENT_JOB_EXECUTED - 失败,通过
sys.exc_info获取详细的错误信息,最后防止内存泄漏,清空错误信息堆栈
- 成功,直接将事件状态设置成
关于子类,主要想介绍一下 BasePoolExecutor
BasePoolExecutor
这个是线程池和进程池的基类,从线程池中获取一个线程或进程,然后将 run_job() 扔进去执行就可以了
class BasePoolExecutor(BaseExecutor):
@abstractmethod
def __init__(self, pool):
super(BasePoolExecutor, self).__init__()
self._pool = pool
def _do_submit_job(self, job, run_times):
def callback(f):
exc, tb = (f.exception_info() if hasattr(f, 'exception_info') else
(f.exception(), getattr(f.exception(), '__traceback__', None)))
if exc:
self._run_job_error(job.id, exc, tb)
else:
self._run_job_success(job.id, f.result())
f = self._pool.submit(run_job, job, job._jobstore_alias, run_times, self._logger.name)
f.add_done_callback(callback)
def shutdown(self, wait=True):
self._pool.shutdown(wait)
ThreadPoolExecutor
使用 concurrent.futures 下的线程池 ThreadPoolExecutor
class ThreadPoolExecutor(BasePoolExecutor):
def __init__(self, max_workers=10):
pool = concurrent.futures.ThreadPoolExecutor(int(max_workers))
super(ThreadPoolExecutor, self).__init__(pool)
ProcessPoolExecutor
使用 concurrent.futures 下的进程池 ProcessPoolExecutor
class ProcessPoolExecutor(BasePoolExecutor):
def __init__(self, max_workers=10):
pool = concurrent.futures.ProcessPoolExecutor(int(max_workers))
super(ProcessPoolExecutor, self).__init__(pool)
其它的子类在实现上区别都不是很大,这里就不展开了,有兴趣的可以自己阅读一下~