每次在用 QT 点击编译总是很好奇编译器具体对我的代码做了哪些操作,同时也好奇动态库,静态库等在程序运行中是怎么被程序调用的,于是学习一波 《程序员的自我修养-链接装载与库》,通过这篇博客打卡
学习时间:2019-10-12
静态链接过程
- 预处理 (Pregressing)
- 编译 (Complication)
- 汇编 (Assembly)
- 链接 (Linking)
预处理
预处理过程主要处理那些源代码中以 # 开始的预编译指令 规则如下:
- 将所有的
#define删除, 并且展开所有的宏定义 - 处理所有的条件预编译指令,比如
#if,#ifdef,#elif,#else,#endif - 处理
#include预处理指令, 讲被包含的文件插入到该预编译指令的位置, 这个过程是递归的,也就是说被包含的文件还可能包含其他文件 - 删除所有的注释 “//” 和 “/* */”
- 添加行号和文件名标识,比如 #2 “hello.c” 2, 以便于编译时编译器产生调试用的行号信息及泳衣编译时产生编译错误或警告时能够显示的行号
- 保留所有的 #pragma 编译指令,因为编译器须要使用它们
编译
编译过程就是把预处理完的文件(*.i)经过6步:扫描,语法分析,语义分析,源代码优化,代码生成和目标代码优化后生成相应的汇编代码文件(*.s)
汇编
汇编器是将汇编代码转变成机器可以执行的指令,每一个汇编语句几乎都对应一条机器指令。这一部分主要是通过汇编器as完成,根据汇编指令和机器指令的对照表一一翻译,最后生成目标文件(Object File)(*.o)
链接
https://www.cnblogs.com/linhaostudy/p/8876930.html 可以参考一下这篇博客
整个链接过程中,它就是将几个输入目标文件加工后合并成一个输出文件。
链接的过程主要包括 地址和空间分配,符号决议,重定位等步骤
比如:我们在程序模块 main.c 中使用另一个模块 func.c 中的函数 foo(), 我们在 main.c 模块中每一处调用 foo 的时候必须确切知道 foo 这个函数的地址, 但是由于每个模块都是单独编译的,在编译器编译 main.c 的时候它并不知道 foo 函数的地址, 暂时把这些调用 foo 的指令的目标地址搁置,等待最后连接的时候由链接器去将这些指令的目标地址修正。 这个地址修正的过程叫做重定位, 每个要被修正的地方叫一个重定位入口
学习时间:2019-10-15
目标文件
编译器编译源代码后生成的文件叫做 目标文件, 代码进行预处理编译和汇编,不发生链接
目标文件格式
| ELF 文件类型 | 说明 | 实例 |
|---|---|---|
| 可重定位文件(Relocatable File) | 这类文件包含了代码和数据,可以被用来链接成可置信文件或共享目标文件 | Linux的.o文件 Windows的 .obj |
| 可执行文件(Executable File) | 这类文件包含了可以直接执行的程序 | 比如/bin/bash文件 Windows的.exe文件 |
| 共享目标文件(Shared Object File) | 这类文件包含了代码和数据,可以在2种情况下使用。 一种在链接器可以使用这种文件跟其他的可重定位文件和共享目标文件链接,产生新的目标文件。 第二种是动态链接器可以将这几个这种共享目标文件与可执行文件结合,作为进程映像的一部分运行 |
Linux的 .so,如/lib/glibc-2.5.so Windows的 DLL |
| 核心转储文件(Core Dump File) | 当进程意外终止时,系统可以将该进程的地址空间的内容及终止时的一些其他信息转储到核心转储文件 | Linux下 core dump |
目标文件结构
目标文件中的内容至少有编译后的机器指令代码、数据,除此以外,还有包括链接时需要的比如符号表,调试信息,字符串等信息。
按照这些信息的不同属性,以 段(Segment) 或者叫 节(Section) 的形式存储。程序源代码编译后的机器指令经常被放在 代码段(Code Section) 里,代码段常见的名字有 “.code” 和 “.text”;全局变量和局部静态变量数据经常放在 数据段(Data Section),数据段的名字一般为 “.data”。
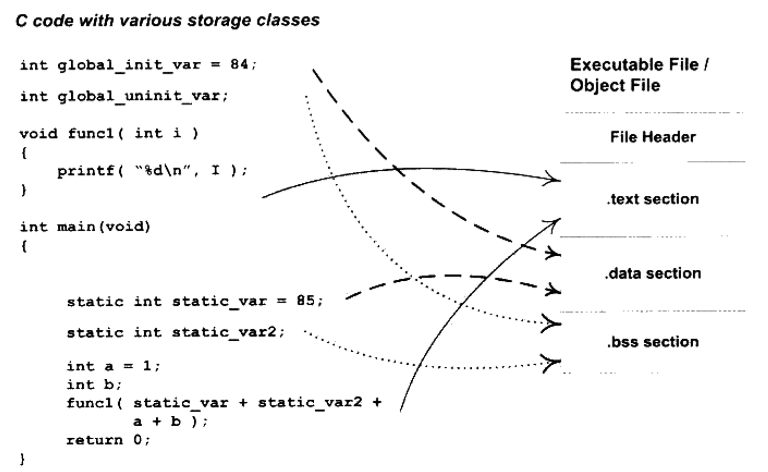
图中的可执行文件(目标文件)的格式是ELF,ELF文件的开头是一个“文件头”,它描述了整个文件的文件属性,包括文件是否可执行、是静态链接还是动态链接及入口地址(如果是可执行文件)、目标硬件、目标操作系统等信息,同事包括一个 段表(Section Table),段表其实是描述文件中各个段的数组,段表描述了文件中各个段是否存在,大小,在文件中的偏移位置及段的属性等,从段表中可以得到每个段的所有信息,文件头后面就是各个段的内容。(不同的编译器可能对某些段的处理存在差异)
程序指令(代码段)和程序数据(数据段和.bss段)分开的原因
- 程序装载后,数据和指令分别被映射到两个虚存区域,由于数据区域对于进程来时是可读写的,而指令区域对于进程是只读的,权限可以分别控制,防止程序指令被有意无意修改
- 现在CPU的缓存一般被设计成数据缓存和指令缓存分离,程序的指令和数据分开对CPU的缓存命中率提高有好处
- 最重要的原因,当系统中运行多个该程序副本,它们的指令都一样,所有内存中只需要保存一份程序的指令部分,对于指令这种只读区域,共享指令可以大大节省空间。
常见段
- .text 段 :一般C语言的编译后执行语句都变成成机器代码
- .data 段 :已初始化的全局变量和局部静态变量保存位置
- .rodate 段 : (Read Only Data)存放只读数据,一般是程序里面的只读变量(如 const 修饰的变量)和字符串常量
- .bss 段 :记录所有未初始化的全局变量和静态变量的大小,只是为未初始化的全局变量和局部静态变量预留位置而已
其他段
| 常用的段名 | 说明 |
|---|---|
| .rodata1 | 跟 “.rodata” 一样 |
| .comment | 存放编译器版本信息, 比如字符串 “GCC:(GNU)4.2.0” |
| .debug | 调试信息 |
| .dynamic | 动态链接信息 |
| .hash | 符号哈希表 |
| .line | 调试时的行号表,即源代码行号与编译后指令的对应表 |
| .note | 额外的编译器信息,比如程序的公司名、发布版本号等 |
| .strtab | String Table 字符串表,用于存储ELF文件中用到的各种字符串 |
| .symtab | Symbol Table 符号表 |
| .shstrtab | Section String Table 段名表 |
| .plt.got | 动态链接的跳转表和全局入口表 |
| .init.fini | 程序初始化与终结代码段 |
学习时间:2019-10-18
ELF文件结构
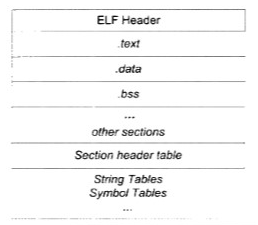
ELF目标文件格式的最前端是ELF文件头,它包含了描述整个文件的基本属性,比如ELF文件版本、目标机器型号、程序入口地址等。然后是ELF文件各个段,其中最重要的是段表(Section Header Table),它描述了文件中包含的所有的段的信息,比如每个段的段名,段的长度,在文件中的偏移、读写的权限及段的其他属性
文件头
ELF文件头中定义了 ELF魔数、文件机器字节长度、数据存储方式、版本、运行平台、ABI版本、ELF重定位类型、硬件平台、硬件平台版本、入口地址、程序头入口和长度、段表的位置和长度及段的数量等等
ELF 文件头结构及相关常数被定义在 “/uer/include/elf.h” 中, 文件头结构有2个版本 “Elf32_Ehdr” 和 “Elf64_Ehdr”, 它们只是部分成员的大小不一样,内容是一样,该文件详细定义了一套自己的变量系统,具体可以自己在 Linux 下查看,有很详细的备注
/* The ELF file header. This appears at the start of every ELF file. */
typedef struct
{
unsigned char e_ident[EI_NIDENT]; /* Magic number and other info */
Elf32_Half e_type; /* Object file type */
Elf32_Half e_machine; /* Architecture */
Elf32_Word e_version; /* Object file version */
Elf32_Addr e_entry; /* Entry point virtual address */
Elf32_Off e_phoff; /* Program header table file offset */
Elf32_Off e_shoff; /* Section header table file offset */
Elf32_Word e_flags; /* Processor-specific flags */
Elf32_Half e_ehsize; /* ELF header size in bytes */
Elf32_Half e_phentsize; /* Program header table entry size */
Elf32_Half e_phnum; /* Program header table entry count */
Elf32_Half e_shentsize; /* Section header table entry size */
Elf32_Half e_shnum; /* Section header table entry count */
Elf32_Half e_shstrndx; /* Section header string table index */
} Elf32_Ehdr;
段表
段表结构比较简单,它是以一个以 “Elf32_Shdr” 结构体为元素的数组,数组元素的个数等于段的个数,每个 “Elf32_Shdr” 结构体对应一个段, “Elf32_Shdr”被称为段描述符 ,sizeof(Elf32_Shdr)为40个字节
/* Section header. */
typedef struct
{
Elf32_Word sh_name; /* Section name (string tbl index) */
Elf32_Word sh_type; /* Section type */
Elf32_Word sh_flags; /* Section flags */
Elf32_Addr sh_addr; /* Section virtual addr at execution */
Elf32_Off sh_offset; /* Section file offset */
Elf32_Word sh_size; /* Section size in bytes */
Elf32_Word sh_link; /* Link to another section */
Elf32_Word sh_info; /* Additional section information */
Elf32_Word sh_addralign; /* Section alignment */
Elf32_Word sh_entsize; /* Entry size if section holds table */
} Elf32_Shdr;
重定位表
字符串表
ELF文件中用到很多字符串,比如段名和变量名等,因为字符串的长度往往是不定的,所以把字符串集中起来存放在一个表,然后使用字符串在表中的偏移来引用字符串,在应用字符串只需要给出一个数字下标,不用考虑字符串长度的问题。
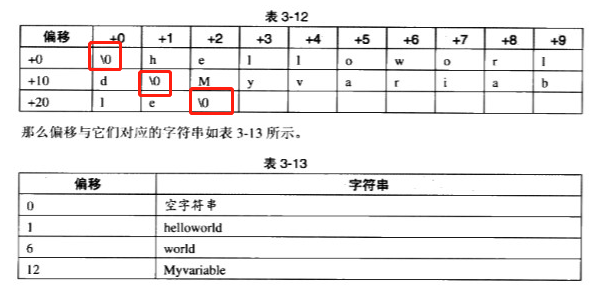
一般字符串表在ELF文件中也以段的形式保存, 常见的段名 “.strtab” (字符串表,用于保存普通的字符串) 和 “.shstrtab” (段表字符串表,用于保存段表中用到的字符串)
学习时间:2019-10-23
链接的接口–符号
链接的本质就是要把不同的目标文件之间拼接成一个整体,实际上是目标文件之间对地址的引用,即对函数和变量的地址的引用, 为了避免连接过程中不同变量和函数之间的函数,每个函数或者变量都有自己独特的名字,函数和变量统称为 符号,函数名或变量名就是 符号名, 符号就是连接中的粘合剂,整个链接过程都是基于符号才能完成,每一个目标文件都会有一个相应的 符号表(Sysbol Table)
符号表结构
符号表一般是文件中的一个段,段名一般叫 “.systab”, 符号表的结构很简单,它是一个 “Elf32_Sym” 结构的数组
/* Symbol table entry. */
typedef struct
{
Elf32_Word st_name; /* Symbol name (string tbl index) 字符串表的下标 */
Elf32_Addr st_value; /* Symbol value */
Elf32_Word st_size; /* Symbol size */
unsigned char st_info; /* Symbol type and binding */
unsigned char st_other; /* Symbol visibility */
Elf32_Section st_shndx; /* Section index */
} Elf32_Sym;
符号修饰和函数签名
为了防止符号名冲突:
C语言规定,C语言源代码文件中所有的全局的变量和函数经过编译以后,相对应的符号名全部加上下划线 “_”,例如一个C语言函数 “foo”,那么他编译后的符号名就是 “foo_”
这种简单而原始的方法确实能够暂时减少 多种语言 目标文件之间的符号冲突的概率,但是没有从根本上解决符号冲突的问题
C++ 引入 namespace 的方法解决多模块的符号冲突问题,语言层次的解决此问题
实际上编译过程中 C++ 解决此问题的方法是 符号修饰(Name Decoration) 或 符号改编(Name Mangling)
例如下面这个例子,这里有6个 func 函数,但是返回类型和参数及命名空间各有不同:
int func(int);
float func(float);
class C {
int func(int);
class C2{
int func(int);
};
};
namespace N {
int func(int);
class C {
int func(int);
};
}
标识一个函数到底是谁,主要通过函数签名(Function Signature),函数签名包含了一个函数的信息,包括函数名、它的参数类型、它所在的类和命名空间及其他信息。在编译器及链接器处理符号时,它们使用 名称修饰 的方法,使得每个函数签名对应一个修饰后的名称。编译器在将C++源代码编译成目标文件时,会将函数和变量的名字进行修饰,形成符号名,也就是说,C++编译器和链接器都是用符号来识别和处理函数和变量
| 函数签名 | 修饰后名称(符号名) |
|---|---|
| int func(int) | _Z4funci |
| float func(float) | _Z4funcf |
| int C::func(int) | _ZN1C4funcEi |
| int C::C2::func(int) | _ZN1C2C24funcEi |
| int N::func(int) | _ZN1N4funcEi |
| int N::C::func(int) | _ZN1N1C4funcEi |
GCC 的基本C++名称修饰方法如下:
所有符号的都以 _Z 开头,对于嵌套的名字(在命名空间或在类里面的),后面紧跟 N , 然后是各个名称空间和类的名字,每个名字前是名字字符串的长度,在以 E 结尾,它的参数列表紧跟在 E 后面或者函数名称后面,更详细可以参考GCC的名称修饰标准
注意:不同的编译器有不同的名称修饰规则
extern “C”
在符号管理上,C++为了与C兼容,C++有同一个用来声明或定义一个C的符号的 extern “C” 关键字用法
C++编译器会将在 extern “C” 的大括号内部的代码当做C语言代码处理,C++的名称修饰机制将不会起作用
弱符号和强符号
多个目标文件中含有相同名字的全局符号的定义,那么这些目标文件链接的时候将会出现符号重复定义的错误,例如目标文件A和目标文件B都定义了一个全局整形变量 global, 并将它们都初始化,那么链接器将A与B进行链接时会报错,这些符号的定义可以被称为 强符号(Strong Symbol)
对于C++/C 语言而言,编译器默认函数和初始化了的全局变量为强符号,未初始化的全局变量为弱符号, GCC的 __attribute__((weak)) 来定义任何一个强符号为弱符号
如下:
extern int ext; // 外部变量的引用
int weak; // weak 弱符号
int strong = 1; // strong 强符号
__attribute__((weak)) weak2 = 2; // weak2 弱符号
int main() // main 强符号
{
return 0;
}